Introduction
When Google and EDF released their study on mapping air pollution in Oakland, the results of this study gained a lot of attention. The data they released was one of the first datasets that showed how air quality varied by city blocks across East and West Oakland. Previously, air quality measurements in Oakland were available only from a handful of monitors placed at different parts of the city. The study revealed elevated levels of air pollution in many parts of Oakland, especially in neighborhoods near cement plants, and auto body shops that were not obvious before.
As an environmental researcher and a data scientist, I was curious to see if I could combine this dataset collected from repeated on-road sampling with machine learning to predict air quality at different locations in the city where measurements are not available. This could help us get a better understanding of the levels of pollution that individuals are exposed to.
Air quality at any location depends on several factors such as traffic on major streets and highways, emissions from railroads, ports and industrial sources, temporal factors, and other meteorological factors like wind speed and wind direction. After a fair bit of research, I decided to scope my project to explore the following question:
“ Can we build a machine learning model to predict air quality at any location in Oakland based on local meteorological conditions, local sources of emissions such as industries, and traffic on highways?”
I created this web-app which predicts address-level pollutant concentrations of Black Carbon (BC) and Nitrogen Dioxide (NO2) in all Oakland neighborhoods. The web-app provides users an insight into air pollutant concentrations in their neighborhood, helps identify areas with good air quality for purchasing or renting homes, and helps identify ‘hot-spots’ where concentrations are unusually high.
The data analysis and machine learning pipeline to build this web-app are outlined below.
Data Analysis and Machine Learning Pipeline
Target Variable
The dataset collected by scientists at EDF and Google contain concentrations of NO2, BC, and Nitric Oxide (NO) collected over a period of 150 days between June 2015 and May 2016 by Google Street View cars fitted with mobile sensing equipment. The dataset was then aggregated over a one year time period, and the median concentration was generated at a ~30 m scale for Oakland.
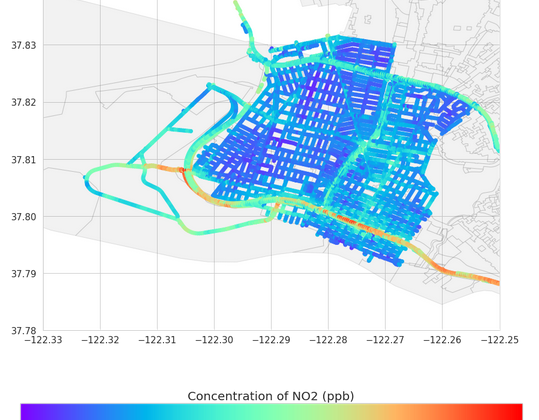
The figure below shows a map of NO2 concentrations measured in the Oakland area. However, this dataset, while certainly very useful, only provides air quality measurements in certain neighborhoods of Oakland.
To use this dataset to build a generalized model that can predict air quality in other neighborhoods in Oakland, I first trained a machine learning model to predict air pollutant concentrations in the same locations as measured in the EDF dataset by creating a set of generalizable features that describe pollutant concentrations. I then used this trained model to predict concentrations at any given address by generating those features for the location of interest.
Let’s first look at how the features were developed based on locations (coordinates).
Input Data and Feature Engineering
In order to develop a feature set that can be used to predict concentrations, we first need to understand how air concentrations at any given location (“location of interest”) correlates with sources of air pollution such as emissions from industries, emissions from traffic, and local meteorological parameters.
I divided the features into the following categories:
Point sources of emissions — I used US EPA’s National Emissions Inventory database [NEI] to get locations of all major point sources in Oakland, and I used the ‘distance between point source and location of interest’ as a metric to measure correlation to concentration.
Traffic — To understand how air pollution at each location correlates with traffic, I used two different traffic metrics as features. The first traffic metric is the number of traffic intersections within a 1,000 ft. radius from the location of interest, and the second metric is proximity (distance) to highways from the location of interest.
Meteorological parameters — To understand how air pollution correlates with annual average meteorological parameters such as precipitation, radiation, min. and max. temperature, and solar radiation, I used Oak Ridge National Lab’s Daymet dataset [Daymet] to get meteorological parameters on a 1km by 1 km grid basis at the location of interest.**
The above figure shows a list of all the input datasets and the machine learning model schema. The final feature set contained 324 features and the target variable here is concentration of NO2 at different locations.
**While wind speed and wind direction definitely play an important role, I ignored those two aspects for the time being since the concentrations measured here are annual averages.
Developing the Machine Learning Model
To build a model to predict concentrations, I tried out five different machine learning algorithms including a simple linear regression model, ridge regression, elastic net, random forest and XGBoost regression. The random forest and XGBoost method resulted in the best predictions. The NO2 dataset was split into test/train data and a 4-fold cross-validation approach was applied to the training dataset. Since the XGBoost had the lowest RMSE (2.69) and highest R2 value (0.925), I chose to implement the XGBoost model to expand the predictions to different neighborhoods.
I used the Random Forest approach to understand which features are most important in predicting concentrations, and to rank the features by importance. The interactive map below shows the location of the top 100 sources (in this case, features) that contribute most to NO2 concentrations in the region. The size of the dots indicates the feature importance, with larger dots indicating higher importance.
Some of the most important features that impact NO2 concentrations in the region include a commercial complex (KTUV Fox 2 office) with generators, the Oakland International Airport, a hospital in San Leandro which may have generators and boilers, and Digital Realty Data Center in Oakland.
Making predictions in different neighborhoods
The next step was to use the model I developed to predict concentrations across a grid of points in the entire Oakland area by generating a feature set for each point across the grid. For each grid point, I used the generated input feature set and the XGBoost model to predict concentrations at that point.
The figure below shows a heatmap of NO2 concentrations predicted across all grid points in different neighborhoods in Oakland, CA.
The Piedmont neighborhood has high concentrations of NO2 which could be primarily due to proximity to major highway (I-580). The blue/green regions near the San Leandro region indicate low concentrations of NO2 since these neighborhoods are farther away from major point sources.
I used the same approach to build a different model to predict BC concentrations.
Conclusions and Next Steps
This work leverages the air pollution monitoring dataset collected by the Environmental Defense Fund in partnership with Google Street View in Oakland to build a machine learning model to predict air pollution concentration at any location of interest using publicly available data on major sources of emissions, number of traffic intersections, proximity to highways and local meteorological data. The model is trained on data points in some neighborhoods in the Oakland area and is built to predict concentrations across a grid of data points in the entire Oakland area.
The heat map generated here is particularly helpful for city planners, environmental management teams and public health experts to predict air quality for any location in East Bay Area, CA, and identifies ‘hot-spots’ or locations where concentrations are unusually high. Another application of this work could be for the public to identify neighborhoods with good air quality for purchasing, renting or selling their houses.
Recently, Google released an air quality dataset containing concentrations measured across all cities in the Bay area, and it would be interesting to build a similar machine learning model to predict concentrations for different cities in the Bay area [Google].
My Github repository for this work, along with a more detailed report can be found here. If you’re interested in knowing more about how the web-app was built, check out my post here!