Author: Tristan Konolige and Sayce Falk
The case for sparsity
As AI models get larger, the importance of each weight for a typical inferencing decreases — a simple sentence fed into OpenAI’s GPT-3, for instance, may activate less than one percent of the model’s 175 billion parameters. In hardware, this means that processors running matrix multiply-based operations for these models are multiplying by zero — a lot. Removing the cost of those useless multiplications can significantly improve model performance.
Block sparsity, where non-zero weights are clustered together, has emerged as the most common approach to skipping multiplications by zero but requires an additional layer of complexity. And while early results have been promising, most hardware chip manufacturers do not provide the ability to implement block sparsity in their vendor-provided kernels. As a result, AI teams are left to attempt to implement sparsity themselves or to leave lossless performance improvements on the table. Neither is a very satisfactory option.
In work we published last year, we showed how to use TVM to leverage block sparsity to accelerate NLP models running on CPUs — a nearly 3X performance improvement on AMD EPYC Rome CPUs (AWS c5a instance type):
Unstructured Sparsity on Nvidia GPUs — faster than cuSPARSE
Now we’re excited to announce that we’ve extended these results to GPUs and unstructured sparsity with similarly impressive performance outcomes.
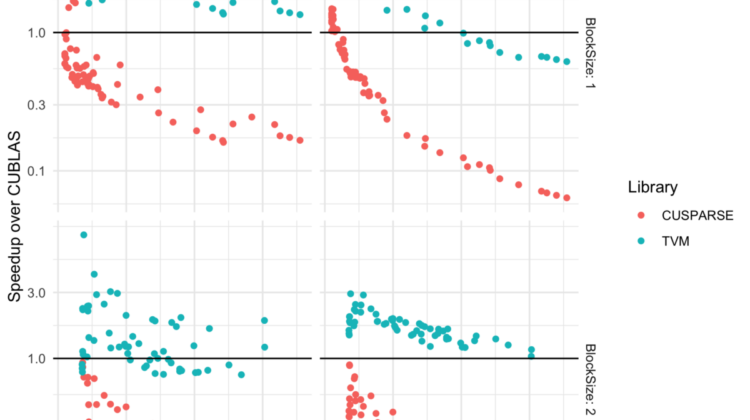
Hardware vendors have provided some implementations of block sparsity in their kernel development — cuSPARSE is the best of this class — but even cuSPARSE struggles on many machine learning problems. And while TensorFlow does offer sparse kernels independent of what NVIDIA provides, they often do not cover new hardware or enable new emerging use cases, meaning sparsity-based optimizations are out of reach for all but the most resource-rich teams.
However, using TVM’s new sparsity-based optimization techniques, we are able to demonstrate nearly 3x performance improvements over NVIDIA’s optimization across batch sizes and in common block sizes (1×1. and 2×2). With these sparse matrix kernels, PruneBERT runs almost 3 times faster than with dense kernels (22ms vs 7.7ms).
We evaluated TVM against cuSPARSE as well, but in all but the most sparse kernel layouts (those with fewer than 5% nonzero entries), cuSPARSE performed more slowly than CUBLAS, and so we generally categorize our performance against CUBLAS. In addition, cuSPARSE only supports standard structured kernels (block sizes of equal length and width), while TVM supports unstructured and structured sparse kernels of any shape. As a result, we’re showing performance for TVM, CUBLAS, and cuSPARSE across standard batch size inputs and kernel block shapes.
As you can see,
One more thing… Sparsity acceleration on AMD GPUs
While the above shows how TVM can enable a single developer (who implemented these kernels) to write faster GPU SpMM kernels for ML applications than NVIDA’s best. We also wanted to show how the cross-platform nature of TVM’s code generation means that these kernels also offer improvements on AMD GPUs as well.
Here you can see that the very same kernels that were faster than NVIDIA’s cuSPARSE and cuBLAS libraries are also up to 3x faster than rocBLAS code on AMD GPUs for matrix sizes and sparsities relevant to NLP machine learning workloads.
NLP Impact
As NLP models running on GPUs continue to be a mainstay for AI teams, these performance improvements enable teams to move towards real-time NLP interactions that consumers and end users expect.
Aside from the technical performance capabilities, these kinds of results can have significant product-level outcomes. NLP model training alone can often entail six figure costs per run, and inferencing after that can represent tens of thousands of dollars a month in cloud costs. With TVM’s performance improvements, product teams can reduce inferencing costs by over 60%, saving many thousands of dollars over the course of a model’s lifecycle.
If your team is interested in talking further about leveraging TVM’s sparse code generation capabilities for your hardware or ML applications, get in touch!
And for teams looking for programmatic access to model optimization, OctoML’s Octomizer is now in Early Access — sign up here to indicate your interest.