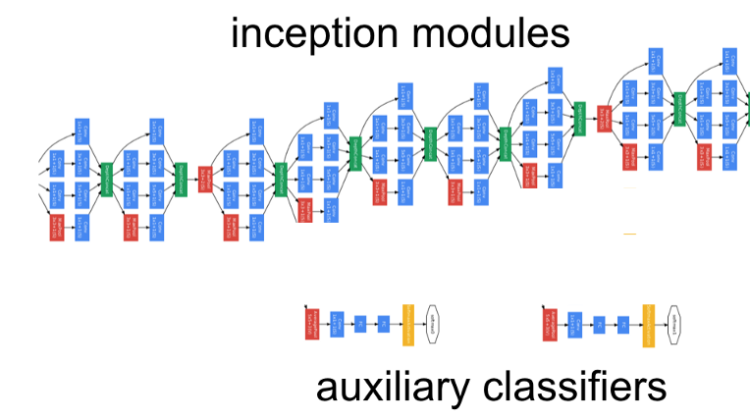
Complete architecture is divided into three-part :
- Stem: It is a starting part of the architecture after the input layer, consist of simple max pool layers and convolution layers with Relu activation.
- Output classifier: It is the last part of the network after flattening the previous layer, consist of a fully connected layer followed by a softmax function.
- Inception module: This is the middle and the most important part of architecture which makes it different from other networks.
Let’s take a deep dive into it.
Here is the ‘naive’ Inception block, Why not have filters with multiple sizes operate on the same level!!
It applies convolutions with 3 different filters size ( 1*1, 3*3, 5*5 ) and max pooling on previous layer output in parallel then concatenate it and sent to the next inception module. Result in concatenating features from different convolutions and max pool in one layer without using separate layers each for different operations.
Do note that, concatenation is only done with the same height and width dimensions, that why padding is applied in each layer to make all with the same dimension.
Above is just a naive inception block, to make it less computationally expensive, 1*1 Conv filter is used before the 3*3 and 5*5 convolution. 1*1 convolutions help in reducing the number of input channels, so when 3*3 and 5*5 convolutions are applied number of multiplication that taken place is now very less so, it helps in making less computational expensive operations.
Do note that however, the 1×1 convolution is also introduced after the max-pooling layer, rather than before. The reason is being the same to reduce the number the channels in output concatenation.
Inception is a deep network, to prevent the middle part of the network from “dying out”(vanishing gradient problem), the authors introduced two auxiliary classifiers. Softmax is applied in each of them and then Auxilary loss is calculated on the same labels of the output classifier.
The total loss function is a weighted sum of the auxiliary loss and the real loss. The weight value used in the paper was 0.3 for each auxiliary loss.
Total loss = real loss + (0.3 * auxiliary loss1) + (0.3 * auxiliary loss2)
Inception v2 works on the same approach as Inception-v1 with some change to make it more efficient in terms of both speed and accuracy.
What’s new
These are some updates in Inception-v2 concerning inception-v1:
- 5*5 convolutions are replaced with two 3*3 convolutions to make it less computationally expensive, we already described 5*5 convolution is 2.28 times more computation expensive than 3*3 convolution, so stacking two 3*3 Conv leads to boasting in performance.
- Some 3*3 convolution is replaced with a combination of 1*3 and 3*1 convolutions. It helps in improving speed and computation. Note that both 1*3 and 3*1 must be applied one after the other, the reason being that 1*3 conv only gives horizontal features(one kind of feature) whereas 3*1 Conv gives vertical features of the input. This method was found to be 33% cheaper than the single 3*3 convolution.
- Some 7*7 convolution is replaced with a combination of 1*7 and 7*1 convolutions.
All the above updates are used to build 3 types of inception blocks and concatenate them to get Inception v2 architecture.
Inception v3 is similar to inception v2 with some updates in loss functions, optimizer, and batch normalization.
What’s new
These are some updates in Inception-v3 concerning inception-v2:
- RMS prop optimizer is used
- Batch normalization is used in the Auxilary classifier
- Label Smoothing (A type of regularizing component added to the loss function that prevents the network from overfitting).
The architecture of the network was made deeper in Inception v4 with the change in stem part (stem refers to the starting part of Inception architecture) and made uniform choices for the Inception blocks.
What’s new
- Change in the stem part
- The number of Inception modules is increased
- Inception modules made more uniform i.e. same numbers of filters are used in modules
- Three types of inception module are named A, B, and C ( similar inception modules as that in inception-v2 )
Inspired by the performance of the ResNet, residual connections are introduced in inception modules.
Input and concatenate output after several operations should have the same dimension, therefore the padding is applied in each operation and at the end 1*1 convolution is applied to make the number of channels equal as shown below.
What’s new
- Residual connections are introduced in inception modules.
- Pooling layer in inception block is replaced by residual connection.
- Network made deeper by increasing the number of Inception modules.
Complete architecture of Inception v2 is