Have you ever thought how computers recognize objects? It is completely different from the way humans identify objects. The Computer understands an image as an array of numbers because they only interact with numbers. Every object has a specific pattern and computer will follow that pattern to identify an object in an image.
A convolutional neural network (CNN) is a neural network that has one or more convolutional layers that assume that the inputs are image. CNNs are mainly used to object recognition, image classification and cluster images. For example, facial recognition, analyzing documents, understanding climate, support autonomous vehicles, etc. There are many CNN architectures now such as, AlexNet, VGGNet, ResNet, etc.
1. Convolutions
CNNs have one or more convolutional layers, these convolutional layers are based on convolution mathematical approach. Convolutional layers use a set of filters to turn input images into filtered output images. It’s like a 2d matrices of numbers.
Applying filters into convolutional layers have few steps. Let’s take an example to explain those steps. Consider below 4×4 image and the 3×3 filter to produce a 2×2 output image.
The numbers in the image represent pixel values, with range of 0–255.
After applying filters convolutional layers will produce a 2×2 image as the output.
Step 1: Overlaying the filter on top of the image at a relevant location.
Step 2: Perform element-wise multiplication between the overlapping image values and filter values.
Step 3: Summing up all the element-wise products.
Sum = (-50)+ (-20)+10+10=(-50)
Then the results of summing up all the element-wise products place in the output image. Since the first filter is overlayed in the top left of the image, results of above operations should place in the top left of the output image.
Step 4: Repeating same scenario for whole input image.
But this output image is 2×2 size, Think if we want to have output image be the same size as the input image. We can use padding into original input image, we can add 0s around the input image to resize the image to get the output in same size as the original image size.
Above describes the main steps of a filtering process of a convolutional neural network. Let’s focus on what actually happens with filter to an image? Above we have used a 3×3 filter, it is commonly known as the vertical sober filter.
Above image is an example of what the vertical Sobel filter does. Mainly these Sobel filters detects edges of the image. There are two types Sober filters,
- Vertical Sobel filter — It detects vertical edges of an image.
- Horizontal Sobel filter — It detects horizontal edges of an image.
After all filtering process by filters it outputs a strong edge around the original image. This edge- detected image is more useful than original image. It gives much detailed image to the network to take decisions.
2. Pooling
When filters work as above discussed, there is a probability to output similar values in neighboring pixels. As a result, much of the detailed data contained in a convolutional layer’s output is redundant. For instance, if we use a filter and find out edge at particular place in the image, and there are chances that we’ll also find relatively edges at locations where 1 pixel shifted from the original one. But these all edges are same, it is not finding anything new.
By pooling layers we can sort out this issue. Pooling layers will reduce the size of the input by giving pooling values together in the input. There are different mechanisms used in practice such as max, min or average. But most of time pooling operation outputs maximum value of the output. As an example of a Max Pooling layer with a pooling size of 2,
Pooling task is easy, after a convolutional layer we just have to traverse the input image in 2×2 blocks (max pooling size=2) and then add max value of the block into the output image at the relevant pixel. This pooling method will divide the input’s width and height by the pool size.
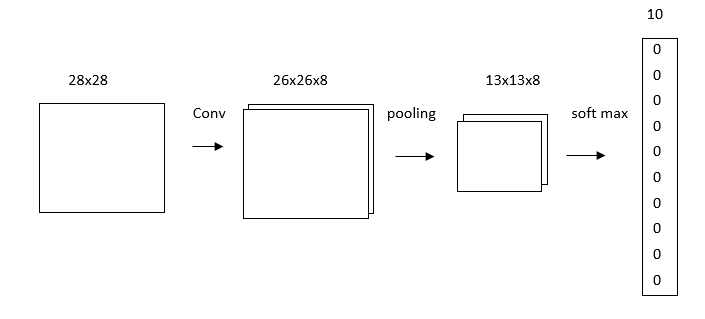
As a instance , if we place a Max Pooling layer with a pool size of 2 after the initial convolutional layer with 8 filters. The pooling layer will transform a 26x26x8 input into a 13x13x8 output.
Note :The output is 26x26x8 and not 28x28x8 because of the padding, which decreases the input’s width and height by 2.
3. Softmax
In the final stage of the CNN, it should output predictions. For a multiclass classification we can use the softmax layer, a fully-connected (dense) layer to make predictions. Fully-connected layers have every node connected to every output from the previous layer.
As an example, if we use softmax layer with 10 nodes, one representing each digit, as the final layer of the CNN. Each node in the layer will be connected to every input. After softmax layer, Output of the CNN will be the digit represented by the node with the highest probability.
4. Conclusion
Here we wrap our discussion about convolutional neural networks. We have discussed about the background of CNNs, convolutional layers , pooling layers and softmax layers. In this post, it was expected to provide basic understanding about convolutional neural networks.