@Task — We have given sample Iris dataset of flowers with 3 category to train our Algorithm/classifier and the Purpose is if we feed any new data to this classifier, it would be able to predict the right class accordingly.
Now we start with importing few python library for reading data file or visualizing our data points. To download Iris dataset Click here and for getting ipython notebook, link is mention below.
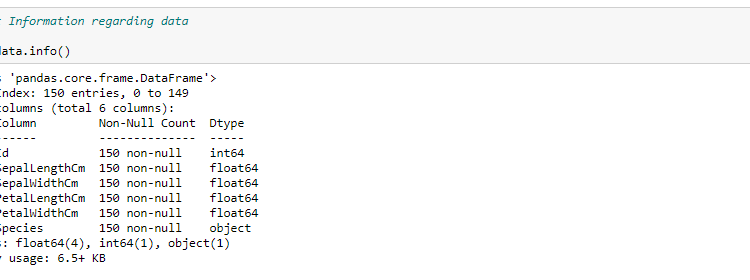
After reading the csv file data, now we explore the dataset and get some basic understanding regarding dataset..
Iris_data contain total 6 features in which 4 features (SepalLengthCm, SepalWidthCm, PetalLengthCm, PetalwidthCm) are independent features and 1 feature(Species) is dependent or target variable. And Id column is like serial number for each data points.
All Independent features has not-null float values and target variable has class labels(Iris-setosa, Iris-versicolor, Iris-virginica)
With “Iris_data.describe()” function we get some numerical information like Total datapoints count, mean value, standard deviation value, 50 percentile value etc. for each numeric feature in our dataset. This will help us to understand the some basic statistic analysis of data.
As we saw that each classes (Species) has equal number of data points, So our Iris data said to be Balanced dataset. No Class is fully dominating in our dataset.
For Visualizing the dataset we used Matplotlib or seaborn as a python library. Their are many plots like scatter, hist, bar, count etc. to visualized the data for better understanding…
By looking the Scatter plot we can say that all bluepoints(Iris-setosa) are separated perfectly as compare to orange(versicolor) or green(virginica) points for features(SepalLengthCm, SepalwidthCm)
By looking the result of pair plot we sure that all blue points are well separated with other two classes. But Versicolor and virginica are partially overlapping with each other.
In pair plot we saw that their are some feature combination which has very less overlapping b/w Versicolor and virginica, that’s means those feature are very important for our classification task purpose.
Here I just try to find some new feature with the help of existing features. Taking difference of each feature with each other to get some more information and visualized it by using plots.
Now finding relationship b/w new feature based on class labels using pair plot.
- With help of Pair plot we are getting some new information but it is more likely similar with our main data features as we saw earlier.
Every combination well separate the Iris-setosa but has some overlapped b/w Versicolor and virginica.
First we need to drop Id column as it is of no use in classifying the class labels..
Visualizing Decision Tree using graphviz library
As our model has been trained….
Now we can validate our Decision tree using cross validation method to get the accuracy or performance score of our model.
- As we know our selected feature are working well and model gives very good accuracy score on validate or actual test data.
- So Now we can trained our model on Actual train dataset with selected features for evaluating/ deploying our model in real world cases.
‘’’Training model on Actual train data… ‘’’
Final Decision tree build for deploying in real world cases….
Checking the performance of model on Actual Test data…
This is how we read, analyzed or visualized Iris Dataset using python and build a simple Decision Tree classifier for predicting Iris Species classes for new data points which we feed into classifier…
If you want to get the whole code then the link for Iris dataset and ipython notebook(.ipynb) is here.