This article tries to pragmatically answer the question asked by many beginners in data science or machine learning “K-Fold cross validation or Hold-Out cross validation: Which one should I use?”
Hold-Out cross validation involves splitting the data into two portions.
- Training set: Portion of data used to train a model.
- Test set: Portion of data used to test the performance of the trained model on unseen data.
In practice, it is advised to also have a third portion:
3. Validation set: Portion of data used to tune the model hyperparameters to achieve better performance. Validation set prevents the model from being overfit to the test set.
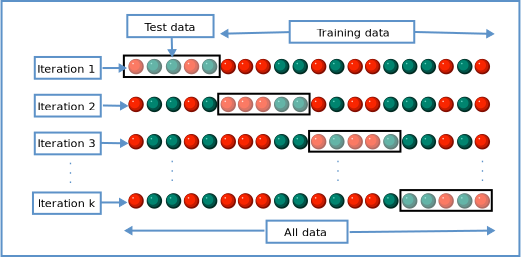
K-Fold cross validation splits the data into ‘k’ portions. For example, in case of 3-fold cross validation, the data is split into three portions (1,2,3).
- In the first iteration, the model is trained on portions 1 &2 and is tested on portion 3. The train score and test score are recorded.
- In the second iteration, the model is trained on portions 2 & 3 and is tested on portion 1. The train score and test score are recorded.
- In the third iteration, the model is trained on portions 1 & 3 and is tested on portion 2. The train score and test score are recorded.
The process is illustrated in the image below
The 3-fold cross validation returns three training scores and three test scores of the three folds.
Now let us find out which method is better through an example. This example fits a Logistic Regression model to the well known Iris data.
First we’ll import the required packages.
import pandas as pd
from sklearn.model_selection import train_test_split,StratifiedKFold,cross_validate
from sklearn.datasets import load_iris
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
In the above list of modules
train_test_split is used to split the data into training set and test set.
StratifiedKFold splits the data into ‘k’ portions such that each portion has the same class distribution as the source data.
cross_validate performs k-fold cross validation and returns the results.
Next, we’ll load the Iris data from Scikit-Learn.
X = load_iris()["data"].copy()
y = load_iris()["target"].copy()
Practical Implementation of Hold-Out Cross Validation
Splitting the data into train and test_val sets.
X_train,X_test_val,y_train,y_test_val = train_test_split(X,y,test_size=0.3,random_state=11)
Splitting the test_val set into ‘test’ and ‘validation’ sets.
X_val,X_test,y_val,y_test = train_test_split(X_test_val,y_test_val,test_size=0.15,random_state=11)
Initializing the logistic regression model and fitting it to the training set.
lr = LogisticRegression(random_state=11,max_iter=1000)
lr.fit(X_train,y_train)
Predicting the validation set using the trained model and finding the accuracy score.
pred = lr.predict(X_val)
accuracy_score(y_val,pred)
The accuracy score on the validation set is 0.92. Now let us make the final prediction on the test set which is considered to be the unseen data and find the accuracy score.
f_pred = lr.predict(X_test)
accuracy_score(y_test,f_pred)
The accuracy score on the test set (unseen data) is found to be 1.0. The difference in the accuracy scores on validation set and test set found using hold-out cross validation is huge.
Practical Implementation of K-Fold Cross Validation
Let us use the data splits we used for hold-out cross validation so that the results can be compared.
In practice, dividing the data into training and test sets is enough for k-fold cross validation as we split the training data into ‘k’ folds and use them for validation.
Now we’ll initialize the ‘kfold’ variable which will be used for cross validation. ‘n_splits=3′ means 3-fold cross validation.
kfold = StratifiedKFold(n_splits=3,random_state=11,shuffle=True)
Next, we initialize the cross validation process by setting ‘accuracy’ as scoring metric, and ‘kfold’ as cross validation parameter.
cv_result = cross_validate(estimator=lr,
X=X_train,
y=y_train,
scoring="accuracy",
cv=kfold,
return_train_score=True)
The following metrics are returned by the cross validation method.
cv_result.keys()
Let us see the validation set scores of the three folds
cv_result["test_score"]
Let us calculate the mean of the above validation scores to get a single number metric for comparison.
cv_result["test_score"].mean()
The mean validation score using k-fold cross validation is 0.98, compared to 0.92 of hold-out cross validation.
We saw earlier that the accuracy score on the test set (unseen data) was 1.0, which is very close to the validation score of k-fold cross validation (0.98) vs the validation score of hold-out cross validation (0.92).
How Did K-Fold Cross Validation Perform Better?
In a way, the k-fold cross validation is tested on all the data. The model is tested on all the examples of data vs a subset of data in the hold-out cross validation. This allows k-fold cross validation to come out with a performance metric that’s closer to the real world metric. However, K-Fold cross validation performs well only when the data used for training and testing is unbiased and represents the real world data which the model would predict in production.
Can We Always Use K-Fold Cross Validation?
It is better to use hold-out cross validation when the data is huge. Huge data sets ensure that the validation set fairly represents the real world data. Also, performing k-fold cross validation on huge data demands huge amount of system resources and is also time consuming.
Hence, it is pragmatically proved that k-fold cross validation performs better than hold-out cross validation in coming out with a performance metric that is closer to the one in the real world.