5 minutes for 5 hours’ worth of reading
Predictably, most of the reading I did this week came through two sources: (1) what others were sharing (on LinkedIn, Twitter, newsletters or directly with me); and (2) what I read when preparing for work-related projects. I generally like to combine these because the first usually widens my horizons and the second deepens my understanding.
Can you tell, which article came from which source?
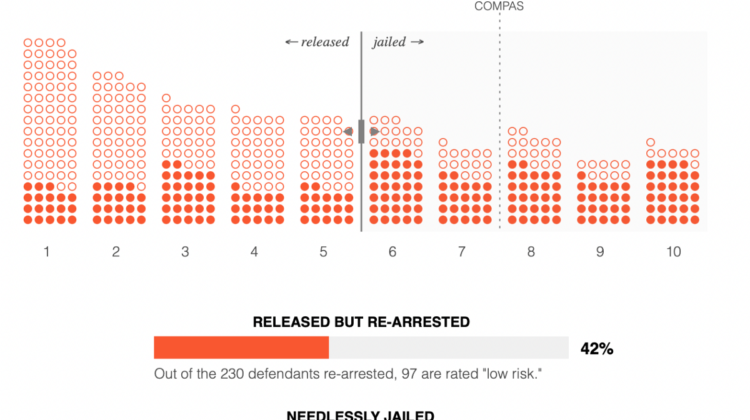
- Can you make AI fairer than a judge? Play our courtroom algorithm game: With the rise of AI & ML, models and engines are making decisions influencing people’s lives. One question being raised is: How can you mathematically quantify fairness? The problem is that fairness means different things in different contexts. A potential solution might be to require companies to audit their machine-learning systems for bias and discrimination in an ‘impact assessment’. That way, companies would be transparent on how they approach the fairness question, plus it will also bring public accountability back into the debate. (MIT Technology Review)
- Feature Store vs Data Warehouse: With more and more machine learning models making their way into production, some problems are seen in a different light. Historically, data scientists have been creating tables with features in the data warehouse to make the development of the models easier. Often, these feature tables were also often used for scoring during a night job, returning the scores back to the data warehouse. Is it still enough? No, it is not. If you are serving features to online models or you want to simplify other features-oriented tasks in the ML pipelines. (Jim Dowling @ Feature Stores for ML)
- How COVID-19 is disrupting data analytics strategies: Forecasting is typically based on data from the past, as it’s the best we have. The current pandemic has made most past data useless for forecasting. So, what now? Companies are using simple(r) models, relying more on external data and trying to incorporate what will happen with Covid-19. Some are also using the current situation to create disaster models for the future. The last point is imho important. We’ll often need to disregard data from this period in the future, but there is a silver lining — it doesn’t mean the data is useless. (MIT Sloan)
- Three mysteries in deep learning: Ensemble, knowledge distillation, and self-distillation: The article discusses theoretical background (almost using popular-science language) behind the three mysteries in deep learning. It provides an intuition (theoretical foundations can be found in the related paper) behind the performance boost provided by using ensemble, knowledge distillation and self-distillation. Especially the self-distillation boost is surprising, and the authors view it as an implicitly combining ensemble and knowledge distillation. (Microsoft Research Blog)
I’ve also learned a new term this week — just-in-time learning. As I’m a big believer in data science being a craft and not a theoretical field, just-in-time learning resonates with me strongly. Your progress is then directly related to the difficulty of problems you are facing.