I write most of my Python programs in Google Colab because it is a free online Jupyter Notebook that has many libraries already installed on it. The advantage of using this platform is that it is relatively easy to use and can be accessed from any computer that has internet and Google connectivity.
Google Colab comes with csv files for two sets of datasets, and these datasets can be practiced on before deciding to go on to more complicated work, such as Kaggle competitions.
The dataset I have made a prediction on is the California House Prices dataset that can be found in Google Colab’s sample files. I found this dataset a delight to work on because:-
- California House Prices does not have any null values that need to be imputed.
- California House prices does not have any categorical columns that need to be converted to numerical columns.
To begin with, I created the ipyn file and copied the path of the two California House Price datasets:-
I then imported the four libraries that I would need to make the predictions, being numpy, pandas, matplotlib and seaborn:-
- Numpy is a library used to make numerical calculations,
- Pandas is a library used to perform data processing and is built on top of numpy,
- Matplotlib is a library that carries out graphical operations,
- Seaborn is a library that has been built on top of matplotlib and also performs graphical operations:-
I then loaded and read the California House Price datasets into the program:-
I made the decision to form one large train file because the test file is much larger than the train file. In addition, both the test and train files have targets assigned to them, which is a peculiarity to the datasets.I used the append() to carry out this operation:-
I checked for information about the train dataset and dound all of the columns are numeric, being floats.
I checked for any null values and was pleased to see there were no null values that needed to be imputed:-
I used the seaborn library to create a plot of the median house prices.
I then used matplotlib to create a scatter plot of median house prices based on the median income:-
I then used seaborn to create box plots of median house prices based on the median house age:-
I also used seaborn to create a heat map of how the independent values impact the target:-
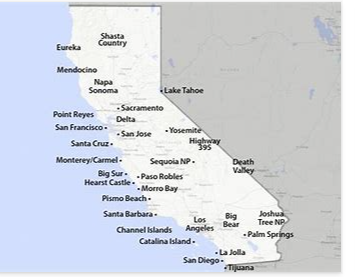
I used seaborn to create a map of the California based on the latitude and longitude of the area:-
After the graphical analysis had been performed, I defined the X and y values. The target is the y variable and is the median house price. The X variable is composed of the independent variables in the dataset.
I used the sklearn’s StandardScaler() function to scale the X variable to the same levels as the target variable.
I split the X dataset up into training and validation sets by using sklearn’s train_test_split() function.
I then defined the model and used sklearn’s HistGradientBoostingRegressor() because it is a regressor designed specifically for large datasets. I achieved 99.41% accuracy using this model:-
Once the model had been defined, I made predictions on the validation set and achieved 85.84% accuracy.
I then used matplotlib to plot a graph of the training target, validation target, and predictions:-
Finally, I created a dataframe to compare the actual values against the predicted values:-
I hope you enjoyed studying the California House Prices and maybe you will want to give it a try before moving on to more complicated work.
The code for this post can be found in its entirety in my personal GitHub account, the link being found here:- House-Prices/California_House_Prices.ipynb at master · TracyRenee61/House-Prices (github.com)