Learning curves leave important clues on performance of a machine learning model, most beginners ignore them.
Lets first understand what is a learning curve in machine learning context.
I assume you are aware of following.
You need machine training dataset, development data set and a test dataset*. Please read previous articles if you are not clear with this.
Machine learning algorithms reads training data and creates a machine learning model.
The built model has training accuracy for its performance execution on the trained data.
The built model also has development accuracy for its performance execution on the development dataset.
These measures you should be clear about already.
Apply this to a cat recogniser, an example of image recognition model. (Most android mobiles can already recognise the breed of cat and the breed of dog as well. Open your image, select the google lens icon, it has the ability to identify breed of your pet now.)
Now let us train our model by giving data in a staggered manner. Say for example we have total 1000 images. We split 700 for training, 200 for development and 100 for test.
Out of 700 images instead of giving all images at once. Train model by giving image inputs incrementally, say first 100, next add few more and give 200 and etc. Keep adding until set is exhausted.
During every iteration we would have got an accuracy value. Calculate error rate. If accuracy was 90% then rate is 10%. Now plot this error rate. Image (1)
The change of error value for different amounts of data we give input when visualised gives us the learning curve.
Plot similarly the learning curve for development set as well.
Now we should have also defined the optimal error rate.
This graph has training learning curve nearing the optimal cutoff value at 20%. There is no much avoidable bias since difference with optimal error is less.
Whereas learning curve of development set is also nearing optimal error and it meets almost training error, this shows there is no variance in model.
So this has produced an ideal result.
Other things to be noted, if the curve is plateaued then there will be no improvement for addition of more data. This is the important clue we have to observe.
In above image both the curve has plateaued but the optimal conditions are also met so it is fine.
Lets see another case. Image (2)
Here in this image the learning curve of both training set as well as development set is above the optimal error.
This infers two things,
There is high avoidable bias which needs to be reduced.
And there is little variance, which is a good things. Sine the end error rate of both training as well as development is almost similar.
Another information is logically our development error always cannot become lower than training set error.
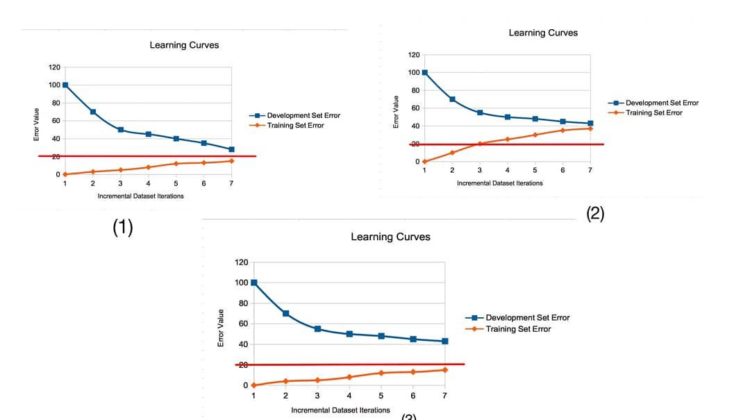
One more final case. Image (3)
Here in this image the learning curve of training set is set to reach optimal error rate, whereas the learning curve of development set started to plateau much above the optimal error rate.
This infers following things,
There is less avoidable bias since it meets already optimal error rate.
But variance is too high since there is bigger difference between development error rate and optimum error value. This variance needs to be addressed.