In regression analysis we fit a predictive model to our data and use that model to predict values of the dependent variable from one or more independent variables.
Simple regression seeks to predict an outcome variable from a single predictor variable whereas multiple regression seeks to predict an outcome from several predictors. We can predict any data using the following general equation:
(Outcome)i = (Model)i + (Error)i
The model that we fit here is a linear model. Linear model just means a model based on a straight line. One can imagine it as trying to summarize a data set with a straight line.
Some Important Features of a Straight Line
A straight line can be defined by two things:
1)The slope or gradient of the line (b1)
2)The point at which the line crosses the vertical axis of the graph, also known as the intercept of the line (b0). So our general equation becomes: Yi = (b0 + b1Xi) + εi
Here Yi is the outcome that we want to predict and Xi is the i-th score on the predictor variable. The intercept b0 and the slope b1 are the parameters in the model and are known as regression coefficients. There is a residual term εi which represents the difference between the score predicted by the line and the i-th score in reality of the de-pendent variable. This term is the proof of the fact that our model will not fit perfectly the data collected. With regression we strive to find the line that best describes the data.
Difference between Correlation and Regression
Correlation analysis is concern with knowing whether there is a relationship between variables and how strong the relationship is. Regression analysis is concern with finding a formula that represents the relationship between variables so as to find an approximate value of one variable from the value of the other(s).
Assumptions of Simple Linear Regression
1. An unilinear between an independent and dependent variable can be represented by a linear regression.
2. The independent variable must be non-stochastic in nature, i.e. the variable doesn‘t have any distribution associated with it.
3. The model must be linear in parameters.
4. The independent variable should not be correlated with the error term.
5. The error terms must be independent of each other, i.e. occurrence of one error term should not influence the occurrence of other error terms.
The Method of Least Square
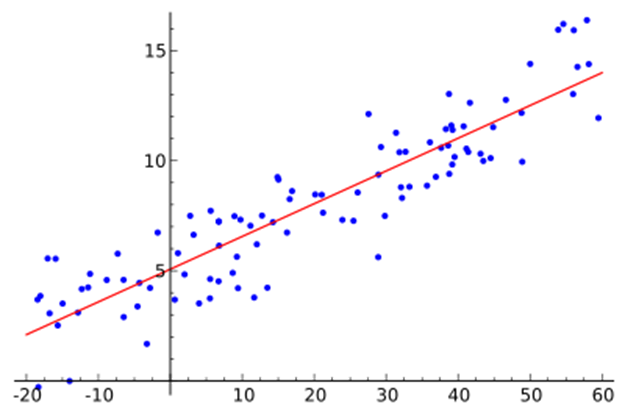
The method of least squares is a way of finding the line that best fits the data. Of all the possible lines that could be drawn, the line of best fit is the one which results in the least amount of difference between the observed data points and the line.
The figure shows that when any line is fitted to a set of data, there will be small differences between the line and the actual data. We are interested in the vertical differences between the line and the actual data because we are using the line to predict the values of Y from the values of X. Some of these differences are positive (they are above the line, indicating that the model underestimates their value) and some are negative (they are below the line, indicating that the model overestimates their value).
Understanding The Goodness of Fit
The goodness of fit of a statistical mod-el describes how well it fits a set of observations. Measures of goodness of fit typically summarize the discrepancy between observed values and the values expected under the model in question.
In linear regression, the fit is expressed through R2, apart from R2, there is another measure of goodness of fit known as Adjusted R Square. The R2 value for a regression can be made arbitrarily high simply by including more and more predictors in the model. Adjusted R2 takes into account the number of independent variables in the model.
From Sample to Population
Like other statistical methods, using regression we are trying to discover a relationship between the dependent and independent variable(s) from a sample and try to draw inference on the population. So there comes the tests of significance in linear regression.
The Equation of the estimated line is:
Here alpha and beta are the estimated value of the intercept and the slope respectively. The tests of significance are related to these two estimates.
Test of Significance of The Estimated Parameters
Global Test
H0: All the parameters are equal to zero simultaneously
H1:At least one is non — zero
This test is conducted by using a F statistic similar to that we saw in ANOVA.
Local Test
For each individual parameters,
H0: The parameter value is zero
H1: The value is non — zero
This test is conducted by using a t statistic similar to a one sample t test.
For Simple Linear Regression there is no difference between the Global and Local tests as there is only one independent variable.
Multiple Linear Regression
The Multiple Linear Regression (MLR) is basically an extension of Simple Linear Regression. Single linear regression has single explanatory variable whereas multiple regression considers more than one independent variables to explain the dependent variable. So from a realistic point of view, MLR is more attractive than the simple linear regression. For example,
(Salary)i = a + b1(Education)i + b2(Experience)i + b3(Productivity)i + b4 (Work Experience)i + (e)i
Assumptions
1. The relationship between the dependent and the independent variables is linear. Scatter plots should be checked as an exploratory step in regression to identify possible departures from linearity.
2. The errors are uncorrelated with the independent variables. This assumption is checked in residuals analysis with scatter plots of the residuals against individual predictors.
3. The expected value of residuals is zero. This is not a problem because the least squares method of estimating regression equations guarantees that the mean is zero.
4. The variance of residual is constant. An example of violation is a pattern of residuals whose scatter (variance) increases over time. Another aspect of this assumption is that the error variance should not change systematically with the size of the predicted values. For example, the variance of errors should not be greater when the predicted value is large than when the predicted value is small.
5. The residuals are random or uncorrelated in time.
6. The error term is normally distributed. This assumption must be satisfied for conventional tests of significance of coefficients and other statistics of the regression equation to be valid.
Concept of Multicollinearity
The predictors in a regression model are often called the ―independent variables‖, but this term does not imply that the predictors are themselves independent statistically from one another. In fact, for natural systems, the predictors can be highly inter-correlated. ―Multicolinearity is a term reserved to describe the case when the inter-correlation of predictor variables is high. It has been noted that the variance of the estimated regression coefficients depends on the inter-correlation of predictors.
How-ever, multicolinearity does not invalidate the regression model in the sense that the predictive value of the equation may still be good as long as the pre-diction are based on combinations of predictors within the same multivariate space used to calibrate the equation. But there are sever-al negative effects of multicolinearity. First, the variance of the regression coefficients can be inflated so much that the individual coefficients are not statistically significant — even though the overall regression equation is strong and the predictive ability good. Second, the relative magnitudes and even the signs of the coefficients may defy interpretation. Third, the values of the individual regression coefficients may change radically with the removal or addition of a predictor variable in the equation. In fact, the sign of the coefficient might even switch.
Signs of Multicollinearity
1. High correlation between pairs of predictor variables
2. Regression coefficients whose signs or magnitudes do not make good physical sense
3. Statistically non-significant regression coefficients on important predictors
4. Extreme sensitivity of sign or magnitude of regression coefficients to insertion or deletion of a predictor variable
What is VIF?
The Variance Inflation Factor (VIF) is a statistic that can be used to identify multicolinearity in a matrix of predictor variables. ―Variance Inflation‖ refers here to the mentioned effect of multicolinearity on the variance of estimated regression coefficients. Multicolinearity depends not just on the bivariate correlations between pairs of predictors, but on the multivariate predictability of any one predictor from the other predictors. Accordingly, the VIF is based on the multiple coefficient of determination in regression of each predictor in multivariate linear regression on all the other predictors:
VIFi = 1/(1 — Ri2)
where Ri2 is the multiple coefficient of determination in a regression of the i-th predictor on all other predictors, and VIFi is the variance inflation factor associated with the i-th predictor. Note that if the i-th predictor is independent of the other predictors, the variance inflation factor is one, while if the i-th predictor can be almost perfectly predicted from the other predictors, the variance inflation factor approaches infinity. In that case the variance of the estimated regression coefficients is unbounded. Multicolinearity is said to be a problem when the variance inflation factors of one or more predictors becomes large. How large it appears to be is a subjective judgment. Some re-searchers use a VIF of 5 and others use a VIF of 10 as a critical threshold. The VIF is closely related to a statistic call the tolerance, which is 1/VIF.
Analysis of The Residuals
Analysis of residuals consists of examining graphs and statistics of the regression residuals to check that model assumptions are satisfied. Some frequently used residuals tests are listed below. All these are to check whether the error terms are identically independently distributed.
- Time series plot of residuals: The time series plot of residuals can indicate such problems as non-constant variance of residuals, and trend or autocorrelation in residuals.
- Scatter plot of residuals against predicted values: The residuals are assumed to be uncorrelated with the predicted values. Violation is indicated by some noticeable pattern of dependence in the scatter plots.
- Scatter plots of residuals against individual predictors: The residuals are assumed to be uncorrelated with the individual predictors. Violation of these assumptions would be indicated by some noticeable pattern of dependence in the scatter plots, and might suggest transformation of the predictors.
- Histogram of residuals: The residuals are assumed to be normally distributed. Accordingly, the histogram of residuals should resemble a normal probability density function curve.
- Lag-1 scatter plot of residuals: This plot also deals with the assumption of independence of residuals. The residuals at time t should be independent of the residuals at time t-1. The scatter plot should therefore resemble a formless cluster of points.
The Idea of Autocorrelation
Autocorrelation is a mathematical representation of the degree of similarity between a given time series and a lagged version of itself over successive time intervals. It is the same as calculating the correlation between two different time series, except that the same time series is used twice — once in its original form and once lagged one or more time periods.
Autocorrelation is calculated to detect patterns in the data. In the chart, the first series is random, whereas the second one shows patterns.
Durbin-Watson (D-W) Statistic
The Durbin-Watson (D-W) statistic tests for autocorrelation of residuals, specifically lag-1 autocorrelation. The D-W statistic tests the null hypothesis of no first-order autocorrelation against the alternative hypothesis of positive first-order autocorrelation. The alter-native hypothesis might also be negative first-order autocorrelation. Assume the residuals follow a first-order autoregressive process
et = pet-1+ nt
where nt is random and p is the first-order autocorrelation coefficient of the residuals. If the test is for positive autocorrelation of residuals, the hypotheses for the D-W test can be written as H0: p = 0 against H1: p > 0
The D-W statistic is given by d = Σ(ei — ei-1)2 / Σei2
It can be shown that if the residuals follow a first-order autoregressive process, d is related to the first-order autocorrelation coefficient, p, as d = 2 (1 — p).
The above equation implies that
d = 2 if no autocorrelation (p = 0)
d = 0 if 1st order autocorrelation is 1
d = 4 if 1st order autocorrelation is -1