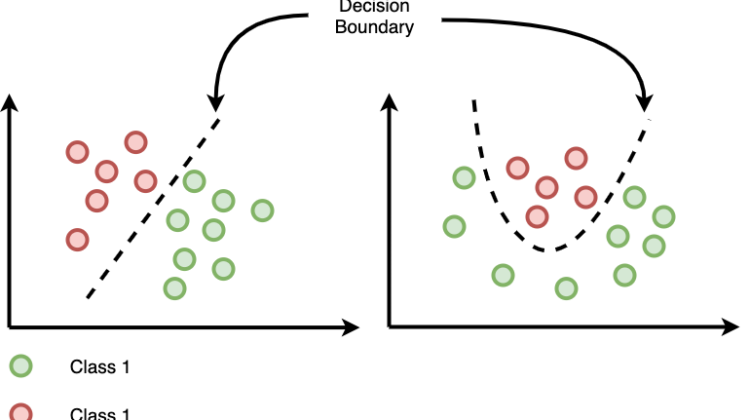
Logistic regression is a Classification algorithm that will draw a boundary to differentiate between 2 or more classes, the boundary can be linear or non-linear.
The starting logic is same as in the linear regression where we have a cost function that is the difference between the real dependent variable values and the decision boundary values.
But since this is a classification (and for more clearer explanation we consider a binary classifications), then the hypothesis function should output values between 0 and 1, and is expressed by the following Sigmoid function:
The downside of this function that once it is plugged into our cost function, the cost function will not be convex (with local minima = global minima) but will have lots of local minimas, hence it is hard to catch the global minima.
To overcome this, we use the logarithm of this function in the following way:
Or in a more compact way, applied to all data points we get:
As for finding the optimal θ that will minimize this cost function, we use the gradient descent in the same way it is used for linear regression, the only difference is that the cost and hypothesis functions are different.
It is important to notice that gradient descent is far from being the only algorithm that can find optimal θ, there are many more.
Multi-class classification:
When our data is labeled by more than 2 classes (K classes), easiest way is to use the one vs. all method where we train K classifiers, each classifier will classify if a new data belongs to that class or not.
We will end up with K classifiers, once we have an input to classify we take the most confident classifier (the classifier that outputs the highest probability)
References:
- Andrew NG machine learning course on coursera