The K Nearest Neighbour also known as KNN algorithm is a powerful classification algorithm used in pattern recognition and is one of the most used data mining algorithms in practice today. It is a non-parametric, supervised learning classification algorithm but can also be used in regression. This algorithm stores all available cases and classifies new cases supported a similarity measure.
Now if all those terms didn’t ring a bell, bother not we are going to unpack all that. So let’s break down these key terms.
In a supervised learning model, the algorithm learns on a labelled dataset, that is data is categorised, providing an answer key that the algorithm can use to evaluate its accuracy on training data. A supervised learning algorithm learns from labelled training data, helps you to predict outcomes for unforeseen data. Scaling data, successfully building and using accurate supervised machine learning Data science model takes time and technical expertise from a team of highly skilled data scientists. Also a Data scientist needs to rebuild models to form a view that the insights given remains true until its data changes. Let’s understand it better with an example:
Taking the example of Image classification which is a popular problem in the computer vision field. Our aim is to predict what class an image belongs to. In this set of problems, we have an interest find the category label of a picture . Saying that, we want to categorise the images of domestic animals say we have cats, dogs and cows, now as the image comes up, we categorise it into the given class.
Now we have emphasised on the word a lot let me tell you what it means. Classification may be a task that needs the utilization of machine learning algorithms that find out how to assign a category label to examples from the matter domain. An easy-to-understand example is classifying emails as whether they are spam or not spam.
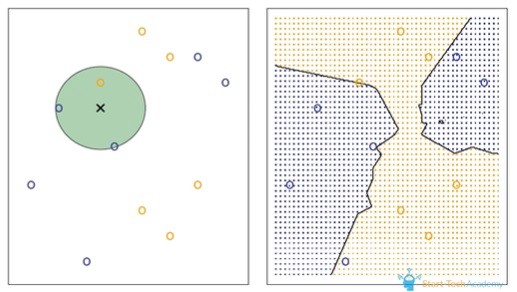
The KNN algorithm works on similarity criteria that is, the things similar to each other exist in close proximity.
An object in this algorithm is classified by a majority of votes for its neighbour classes, meaning the object is assigned to the most common class among its K nearest neighbours that is measured by a distance function.
One of the most crucial steps in this algorithm is choosing the optimal value for K. This is best done by first inspecting the data. In general, a large K value is more precise as it reduces the overall noise but it would still be suggested to overview the data.
Let us simplify this method through a step-wise procedure.
Algorithm steps:
1. Load the dataset
2. Initializing K to your chosen number of neighbours
3. For each example in the data
· Calculate the space between the query example and the given the current example from the information
· Add the space and the index of the instance to an ordered collection
4. Now sort the ordered collection of distances and indices in ascending order by using the distance function
5. Pick the primary K entries from the sorted collection
6. Get the labels of the chosen K entries
7. If in case of regression, return the mean of the K labels
8. If in case of classification, return the mode of the K labels
Distance Function
Since K nearest neighbours are measured by a distance function. Here is a list of a few that can be utilised for the same.
Although it should also be noted that all three distance measures are only valid for continuous variables. In the instance of categorical variables, the Hamming distance function must be used.
Advantages
1)The algorithm is simple and easy to implement.
2)There’s no go to build a model, tuning various parameters, or make additional assumptions.
3)The given algorithm is versatile. It is commonly used for classification, regression, and search.
Drawbacks
Some of the drawbacks includes:
1)Tie/Equal Probability Cases: These arise when two classes have equal probability for an object in a given K value.
The solution for this is,
i)Using odd values of k for 2 case problems
ii)K must not be a multiple of number of classes
2)Complexity: The main drawback of KNN is the complexity in searching the nearest neighbour in each sample. The algorithm gets significantly slower because the number of examples and/or predictors/independent variables increase.
The k-nearest neighbours’ algorithm is a simple, supervised machine learning algorithm that can be used to solve both classification and regression problems
KNN works by finding the distances between a question and every one the examples within the data, selecting the required number examples (K) closest to the query, then votes for the most frequent label ,in case of classification or averages the labels ,in the case of regression.
In the case of classification and regression, we saw that choosing the proper K for our data is completed by trying several Ks and picking the one that works best. It’s easy to implement and understand, hence it is a great starting point for machine learning.