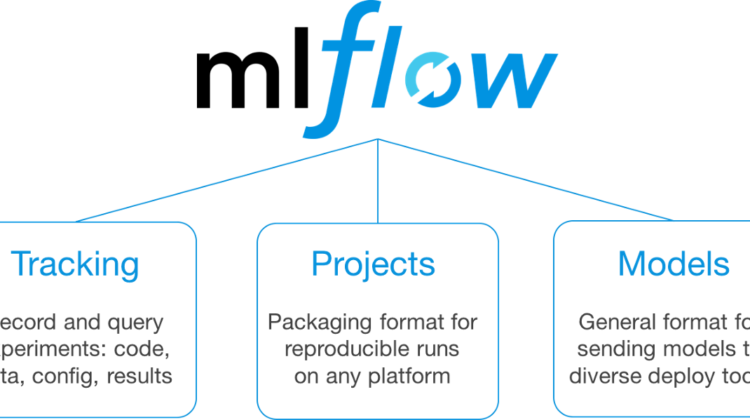
We have several options which we are going to take a look:
At the left panel, we are going to see our experiments, which we’ll help us to group different runs of a same problem, there is an experiment Called “Default”, lets edit it to rename it “Wine Regression” and we can create another one called Iris.
Now, create a file named train.py and put this code:
import warnings
import sys
import pandas as pd
import numpy as np
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
from sklearn.model_selection import train_test_split
from sklearn.linear_model import ElasticNet
import mlflow.sklearnimport logging
logging.basicConfig(level=logging.WARN)
logger = logging.getLogger(__name__)
mlflow.set_tracking_uri('http://localhost:5000')
mlflow.set_experiment(experiment_name='Wine Regression')
tags = {"team": "Analytics Principal",
"dataset": "Wine",
"release.version": "2.2.2"}
def eval_metrics(actual, pred):
rmse = np.sqrt(mean_squared_error(actual, pred))
mae = mean_absolute_error(actual, pred)
r2 = r2_score(actual, pred)
return rmse, mae, r2
if __name__ == "__main__":
warnings.filterwarnings("ignore")
# Read the wine-quality csv file from the URL
csv_url = (
"http://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-red.csv"
)
try:
data = pd.read_csv(csv_url, sep=";")
except Exception as e:
logger.exception(
"Unable to download training & test CSV, check your internet connection. Error: %s", e
)
# Split the data into training and test sets. (0.75, 0.25) split.
train, test = train_test_split(data)
# The predicted column is "quality" which is a scalar from [3, 9]
train_x = train.drop(["quality"], axis=1)
test_x = test.drop(["quality"], axis=1)
train_y = train[["quality"]]
test_y = test[["quality"]]
alpha = float(sys.argv[1]) if len(sys.argv) > 1 else 0.5
l1_ratio = float(sys.argv[2]) if len(sys.argv) > 2 else 0.5
with mlflow.start_run(run_name='Sk_Elasticnet'):
mlflow.set_tags(tags)
lr = ElasticNet(alpha=alpha, l1_ratio=l1_ratio, random_state=42)
lr.fit(train_x, train_y)
predicted_qualities = lr.predict(test_x)
(rmse, mae, r2) = eval_metrics(test_y, predicted_qualities)
print("Elasticnet model (alpha=%f, l1_ratio=%f):" % (alpha, l1_ratio))
print(" RMSE: %s" % rmse)
print(" MAE: %s" % mae)
print(" R2: %s" % r2)
mlflow.log_param("alpha", alpha)
mlflow.log_param("l1_ratio", l1_ratio)
mlflow.log_metric("rmse", rmse)
mlflow.log_metric("r2", r2)
mlflow.log_metric("mae", mae)
mlflow.sklearn.log_model(lr, "model")
mlflow.log_artifact(local_path='./train.py', artifact_path='code')
I’ll assume that you are already familiar with machine learning and sklearn, so I’ll only explain the MLflow related code, first you see these lines of code:
mlflow.set_tracking_uri('http://localhost:5000')
mlflow.set_experiment(experiment_name='Wine Regression')
tags = {"team": "Analytics Principal",
"dataset": "Wine",
"release.version": "2.2.2"}
We are telling to mlflow that the server that is up and running is at our localhost and port 5000, and that we want to use an experiment space named Wine Regression. We also have a tags dict which is gonna work as extra metadata that we want to relate to the experiment run.
Then we start our run as a context manager so we can use several methods inside while the run is active, we are gonna name it Sk_Elasticnet so we can remember what are we running:
with mlflow.start_run(run_name='Sk_Elasticnet'):mlflow.set_tags(tags)
mlflow.log_param("alpha", alpha)
#.....
mlflow.log_param("l1_ratio", l1_ratio)
mlflow.log_metric("rmse", rmse)
mlflow.log_metric("r2", r2)
mlflow.log_metric("mae", mae)mlflow.sklearn.log_model(lr, "model")
mlflow.log_artifact(local_path='./train.py',
artifact_path='code')
with the .set_tags method, we link the current run to the tags we defined, using .log_params, we can pass the current parameters tuple (name, value), similar to the .log_metric for our models metrics result.
We also want to save the trained model so we can later use it, for this, we use .log_model, mlflow is gonna create some metadata around it and export it as a cloudpickle file (or just .pickle).
And one of my favorite things of mlflow, we can log custom artifacts using .log_artifact, we can use it to store images related to the training phase, external resources, datasets and even a copy of the code used to generate this run. We are gonna use it with that last use case.
When we run the code and refresh the mlflow UI, you should see something like this