In actual application scenarios, data is stored in an HBase cluster, but due to some special reasons, data needs to be migrated from HBase to Kafka. Under normal circumstances, the source data is usually sent to Kafka, and then consumers process the data and write the data to HBase. However, if reverse processing, how to migrate HBase data to Kafka? Today I will share with you the specific implementation process.
The general business scenario is as follows. The data source generates data, enters Kafka, and then is processed by consumers (such as Flink, Spark, Kafka API) and then enters HBase. This is a very typical real-time processing flow. The flow chart is as follows:
The above-mentioned real-time processing flow is relatively easy to process data, after all, the data flow is processed sequentially. However, if you reverse this process, you will encounter some problems.
1. Massive data
With the distributed nature of HBase and the horizontal expansion of clusters, the data in HBase is often tens of billions, hundreds of billions, or orders of magnitude larger. For this type of data, there will be a very troublesome problem for this kind of reverse data flow scenario, that is, the problem of access. How to extract this massive amount of data from HBase?
2. No data partition
We know that HBase can do data Get or List<Get> quickly and easily. And it does not have the concept of data warehouse partitions like Hive, and cannot provide data for a certain period of time. If you want to extract the data of the most recent week, you may scan the entire table to obtain the data of the week by filtering the timestamp. When the number is small, the problem may not be big, and when the amount of data is large, it is difficult to scan the entire table for HBase.
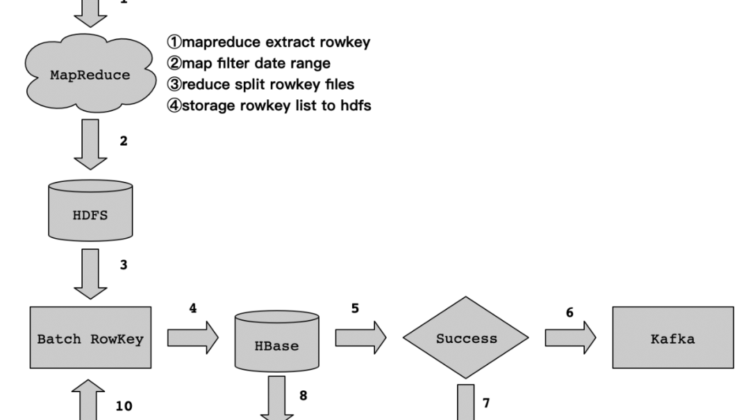
How to deal with this kind of reverse data flow. In fact, we can use the features of HBase Get and List<Get> to achieve this. Because HBase builds a first-level index through RowKey, the speed of access to RowKey level is very fast. The details of the implementation process are as follows:
The data flow is shown in the figure above, and the author will analyze the implementation details of each flow and the matters needing attention.
1. Rowkey extraction
We know that HBase does a primary index for Rowkey access, so we can use this feature to expand. We can extract the Rowkey in the massive data from the HBase table, and then store the extracted Rowkey on HDFS in accordance with the extraction rules and storage rules we set.
There is a problem to pay attention to here, that is about the extraction of HBase Rowkey, the Rowkey extraction of massive data level, it is recommended to use MapReduce to achieve. This is achieved thanks to the TableMapReduceUtil class provided by HBase. Through the MapReduce task, the Rowkey in HBase is filtered according to the specified time range in the map phase, and the rowkey is split into multiple files in the reduce phase, and finally stored on HDFS.
There may be some students who have questions here. They have all used MapReduce to extract Rowkey. Why not directly scan and process the column data under the column cluster? Here, when we start the MapReduce task, we only filter Rowkey (using FirstKeyOnlyFilter to achieve) when scanning HBase data, and do not process the column cluster data, which will be much faster. The pressure on HBase RegionServer will also be much less.
Here is an example, such as the data in the above table, in fact, we only need to take out Rowkey (row001). However, in actual business data, the HBase table describes a piece of data that may have many characteristic attributes (such as name, gender, age, ID, etc.), and some business data may have more than a dozen characteristics under a cluster, but they only have one. Rowkey, we only need this one Rowkey. So, we use FirstKeyOnlyFilter to achieve it is very appropriate.
/**
* A filter that will only return the first KV from each row.
* <p>
* This filter can be used to more efficiently perform row count operations.
*/
This is a functional description of FirstKeyOnlyFilter. It is used to return the first KV data. It is officially used for counting. Here we make a slight improvement and use FirstKeyOnlyFilter to extract Rowkey.
2. Rowkey generation
How to generate the extracted Rowkey, here may be based on the actual order of magnitude to confirm the number of Reduce. It is recommended to calculate the number of Reduces based on the actual amount of data when generating Rowkey files. Try not to use an HDFS file for ease of use, which is difficult to maintain later. For example, if the HBase table has 100GB, we can split it into 100 files.
3. Data processing
In step 1, in accordance with the extraction rules and storage rules, the data is extracted from HBase through MapReduce Rowkey and stored on HDFS. Then, we read the Rowkey file on HDFS through the MapReduce task, and get the data from HBase through List<Get>. The details of the disassembly are as follows:
In the Map phase, we read the Rowkey data file from HDFS, then fetch the data from HBase by batch Get, and then assemble the data and send it to the Reduce phase.
In the Reduce phase, obtain the data from the Map phase, write the data to Kafka, obtain the state information written to Kafka through the Kafka producer callback function, and determine whether the data is written successfully according to the state information.
If it succeeds, record the successful Rowkey to HDFS to facilitate the statistics of the successful progress; if it fails, record the failed Rowkey to the HDFS to facilitate the statistics of the failed progress.
4. Rerun after failure
Writing data to Kafka through a MapReduce task may fail. In case of failure, we only need to record the Rowkey to HDFS. After the task is executed, go to the program to check whether there is a failed Rowkey file on HDFS. If If it exists, then start step 10 again, that is, read the failed Rowkey file on HDFS, then List<Get> the data in HBase, perform data processing, and finally write Kafka, and so on, until the failed Rowkey processing on HDFS So far.
The amount of code implemented here is not complicated. The following provides a pseudo code that can be modified on this basis (for example, Rowkey extraction, MapReduce reads Rowkey and batch Get HBase tables, and then writes to Kafka, etc.). The sample code is as follows:
public class MRROW2HDFS {
public static void main(String[] args) throws Exception {
Configuration config = HBaseConfiguration.create(); // HBase Config info
Job job = Job.getInstance(config, “MRROW2HDFS”);
job.setJarByClass(MRROW2HDFS.class);
job.setReducerClass(ROWReducer.class);
String hbaseTableName = “hbase_tbl_name”;
Scan scan = new Scan();
scan.setCaching(1000);
scan.setCacheBlocks(false);
scan.setFilter(new FirstKeyOnlyFilter());
TableMapReduceUtil.initTableMapperJob(hbaseTableName, scan, ROWMapper.class, Text.class, Text.class, job);
FileOutputFormat.setOutputPath(job, new Path(“/tmp/rowkey.list”)); // input you storage rowkey hdfs path
System.exit(job.waitForCompletion(true)? 0: 1);
}
public static class ROWMapper extends TableMapper<Text, Text> {
@Override
protected void map(ImmutableBytesWritable key, Result value,
Mapper<ImmutableBytesWritable, Result, Text, Text>.Context context)
throws IOException, InterruptedException {
for (Cell cell: value.rawCells()) {
// Filter date range
// context.write(…);
}
}
}
public static class ROWReducer extends Reducer<Text,Text,Text,Text>{
private Text result = new Text();
@Override
protected void reduce(Text key, Iterable<Text> values,Context context) throws IOException, InterruptedException {
for(Text val:values){
result.set(val);
context.write(key, result);
}
}
}
}
The entire reverse data processing process is not complicated, and the implementation is also very basic MapReduce logic, without too complicated logic processing. In the process of processing, you need to pay attention to several details:
When Rowkey is generated on HDFS, there may be line spaces. When reading Rowkey files on HDFS to List<Get>, it is best to filter the spaces for each data. In addition, it is for the records of successful processing of Rowkey and failed processing of Rowkey, which facilitates task failure reruns and data reconciliation. You can know the progress and completion of data migration. At the same time, we can use the Kafka Eagle monitoring tool to view the Kafka write progress.