We have got a new Sheriff in town. The big brother of DevOps…meet MLOps.
ML Models go through multiple iterations in the form of experiments, with data scientists training them on one set of data and testing them on others. Machine Learning Operations(MLOps) is the practice of creating a pipeline from developer to product. DevOps focuses on versions of software whereas MLOps focuses on versions of code, data, and the ML model itself.
Goal: Deploying models in production with complete monitoring and and retraining pipelines.
With MLOps we add two new paradigms to CI/CD practices
- Continuous Monitoring(CM): A ML system is as good as its predictions. The most rigorously trained model can go bad in time due to data changes, model drift and a various other factors. A certain threshold has to be maintained for the model and the system needs to be continuously monitored to capture these changes and trigger model retraining pipeline
- Continuous Training(CT): A model is as good as the data it is being trained on. As time moves forward, the input data might change with it which could lead to bad predictions. The model could be improved through re-training on this newly available data.
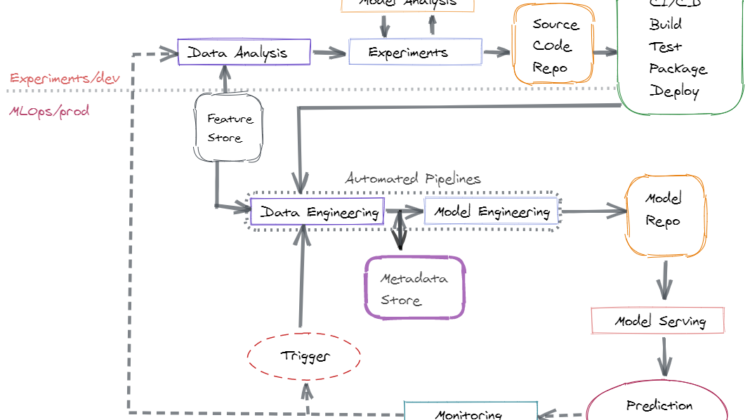
MLOps Pipeline:
The core of an ML system lies at data. Data needs to be gathered form multiple sources and then massaged and transformed for ds use case. Data collection can be done via multiple tools based on the use case at hand. Some of the tools that I use are Pandas, Dask, Spark.
Next After data is gathered, experiments have to be done by the data scientists to extract relevant features and then train the model. Hyper parameters have to be tuned and model training is done iteratively with different versions of data to get the best model. Here two things are super important: data versioning as well as model versioning. For data versioning I prefer DVC and for model versioning, I use MLFlow.
Data extraction is an expensive process and when different data science teams work on the same data to extract same sets of features, all manners of problems can arise. To avoid that, its feasible to use a Feature store where all the up to date features are stored. Some good options here are Feast, Hopsworks.
The above data loading and model engineering are created as pipeline steps. Some of the workflow tools you can use to create these are: Airflow, Kubeflow Pipeline, Argo Workflows.
The code is usually stored in Git or Bitbucket. For build and deployment I use a Jenkins pipeline.
A model can be served in quite a different number of ways. One can use a server like Flask or Gunicorn and deploy the model while exposing a REST Api endpoint. Another option is to deploy it in a kubernetes pod, use Seldon or KFServing. For an edge device, the model needs to be embedded within the application itself. For e.g. on your mobile, the autocorrect on the keyboard is a model that’s hosted within the app itself.
The last is the retraining pipeline that is hooked to the monitoring system. For monitoring, the model input, output and various other metrics are captured using MLFlow. When the model metrics go beyond a certain threshold, the model retraining pipeline is triggered.
Not just training the model but also when to stop training is also important. For those who disagree, the below guy is still filling out his income tax form.