· Importance of Data Lake in Healthcare
In Healthcare, we deal with different facets of data such as Clinical Data, Insurance Data, Financial Data, Equipment/ Manufacturing Data, Pharmacological Data. The primary source of healthcare data is Patient Electronic Health Records (EHR). Health Level Seven International (HL7), a non-profit standards development organization, announced a standard for the exchange of structured medical data called Fast Healthcare Interoperability Resources (FHIR). FHIR has extensive endorsement from healthcare software providers and was supported at a meeting of the American Medical Informatics Association by EHR providers. The FHIR specification makes structured medical data easily accessible to clinical researchers and computer scientists, and it also makes it easier for machine learning tools to process this data and extract valuable information from it. For example, FHIR provides a facility for capturing documents, such as doctor’s notes or lab report summaries. However, this data must be extracted and transformed before it can be searched and analyzed.
In many occasions data silos create biggest challenge to leverage insight from data across it’s different flavor. Data Lake enables organization to analyze data from single source of truth.
A data lake is an architecture used to store data as is, as is, at high speed, at high speed, in a centralized repository for large scale data and real-time analysis. Healthcare facilities can extract vast amounts of data — structured, semi-structured and unstructured — in real time from a data lake, from anywhere. Data can be ingested from Internet of Things sensors, website click stream activity, log files, social media feeds, videos, and online transaction processing systems (OLTP).
· Current Approach for Healthcare Data Lake Implementation
As per conventional method of building data lake on AWS, S3 is one of the key components. It allows us to perform analytics with lake-house (Lake-house is architecture pattern to build data warehouse on top of Data Lake) architecture.
Above illustration depicts one of the existing architectural patterns to build data lake on AWS with healthcare data. This example is taken from AWS Blog. Above architecture deal with ubiquitous electronic health record (EHR), the sources of this data include genome sequencers, devices such as MRIs, x-rays and ultrasounds, sensors and wearables for patients, medical equipment telemetry, mobile applications. Along with medical data, other non-clinical, operational systems data come from different sources such as human resources, finance, supply chain, claims and billing.
Above reference architecture has four distinct components — ingestion, storage, security, and analytics.
Different data ingestion options such as AWS Snowball, AWS Direct Connect, Storage Gateway, AWS Kinesis Services can be used as per given use cases with On-premise data, streaming data or third-party healthcare data. AWS Glue is used to de-identify, ingest healthcare data into S3 and transformation can be performed through Glue ETL on ingested data.
Data resides on S3 Data Lake need to be divided in zones such as Raw Landing Zone, Cleansed Zone and Analytical zones to prevent it from becoming Data Swamp. We can analyze data from S3 using SQL like query using Athena. Redshift spectrum allow to create external table with the data from S3 without physical data transfer and analyze with SQL like query along with data from other Redshift table. By using federated queries in Amazon Redshift, we can query and analyze data across operational databases, data warehouses, and data lakes. With the Federated Query feature, we can integrate queries from Amazon Redshift on live data in external databases with queries across Amazon Redshift and Amazon S3 environments. Federated queries can work with external databases in Amazon RDS for PostgreSQL, Amazon Aurora with PostgreSQL compatibility, Amazon RDS for MySQL (preview), and Amazon Aurora with MySQL compatibility (preview). AWS Glue Elastic Views (Preview) makes it easy to build materialized views that combine and replicate data across multiple data stores without writing custom code. can use familiar Structured Query Language (SQL) to quickly create a virtual table — a materialized view — from multiple different source data stores. AWS Glue Elastic Views copies data from each source data store and creates a replica in a target data store. AWS Glue Elastic Views continuously monitors for changes to data in source data stores and provides updates to the materialized views in target data stores automatically, ensuring data accessed through the materialized view is always up to date. AWS Glue Elastic Views supports many AWS databases and data stores, including Amazon DynamoDB, Amazon S3, Amazon Redshift, and Amazon Elasticsearch Service, with support for Amazon RDS, Amazon Aurora, and others to follow. AWS Glue Elastic Views is serverless and scales capacity up or down automatically based on demand, so there’s no infrastructure to manage.
· Challenges with Current Approach for Healthcare Data Lake Implementation
Whatever the data lake design and implementation options we discussed in previous section require supervision and strong domain knowledge, technical expertise to fulfil multiple use cases in an optimized manner. If we need to extract more value out of data , we have to use different advance analytics options with Machine Learning. Different offering from AWS can be helpful to perform machine learning such Amazon SageMaker, Amazon Transcribe but it needs in-depth understanding of healthcare data with EHR (digital version of a patient’s paper chart. EHRs are real-time, patient-centered records that make information available instantly and securely to authorized users. While an EHR does contain the medical and treatment histories of patients, an EHR system is built to go beyond standard clinical data collected in a provider’s office and can be inclusive of a broader view of a patient’s care.), FHIR (The Fast Healthcare Interoperability Resource is a draft data standard developed and nurtured by HL7 International. FHIR was created with the complexity of healthcare data in mind, and takes a modern, internet-based approach to connecting different discrete elements.) and good understanding of Machine Learning concepts, techniques. It creates another challenge in Data Lake migration with customer’s mindset by thinking about probable complexity with it.
· Modernize Healthcare Data Lake with AWS HealthLake
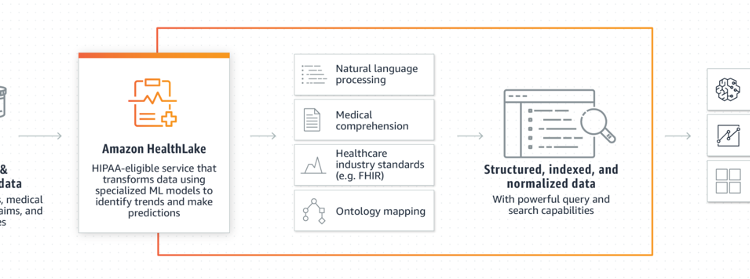
AWS releases Amazon HealthLake during AWS Re: Invent 2020. Amazon HealthLake is a HIPAA-eligible (The Health Insurance Portability and Accountability Act of 1996 (HIPAA) is a federal law that required the creation of national standards to protect sensitive patient health information from being disclosed without the patient’s consent or knowledge. The US Department of Health and Human Services (HHS) issued the HIPAA Privacy Rule to implement the requirements of HIPAA. The HIPAA Security Rule protects a subset of information covered by the Privacy Rule) service that enables healthcare providers, health insurance companies, and pharmaceutical companies to store, transform, query, and analyze health data at petabyte scale.
Discussed challenges with implementation of healthcare data lake in previous section are addressed by Amazon HealthLake in major occasions. It removes the heavy lifting of organizing, indexing, and structuring patient information to provide a complete view of the health of individual patients and entire patient populations in a secure, compliant, and auditable manner. Using the HealthLake APIs, healthcare organizations can easily copy health data in the Fast Healthcare Interoperability Resources (FHIR) industry standard format from on-premises systems to a secure data lake in the cloud. HealthLake transforms unstructured data using specialized machine learning models, like natural language processing, to automatically extract meaningful medical information from the data and provides powerful query and search capabilities. Organizations can use advanced analytics and ML models, such as Amazon QuickSight and Amazon SageMaker to analyze and understand relationships, identify trends, and make predictions from the newly normalized and structured data. From early detection of disease to population health trends, organizations can use Amazon HealthLake to conduct clinical data analysis powered by machine learning to improve care and reduce costs.
Amazon HealthLake maintains Data Stores of health records in FHIR-compliant format. We can perform the following tasks using the Amazon HealthLake console, AWS Command Line Interface (AWS CLI), or APIs:
· Create, monitor, and delete a Data Store
· Import data from an Amazon Simple Storage Service (Amazon S3) bucket into the Data Store
· Query data using Create, Read, Update, and Delete functions
· Use FHIR search functionality
· Transform data using integrated medical natural language processing (NLP)
There are high level 4 steps in HealthLake from data ingestion to business value creation.
1. Creating and monitoring Data Stores
2. Create, Read, Update, Delete (CRUD) operations
3. FHIR search across all data
4. Build ML model using Integrated medical natural language processing (NLP)
Each of the above steps are explained below with screenshot.
1. Creating and monitoring Data Stores : The following example demonstrates how to create a Data Store using the AWS Command Line Interface (AWS CLI) and AWS Console simultaneously.
The following example shows how to use the AWS CLI to create data store
aws healthlake create-fhir-datastore
— region us-east-1
— datastore-type-version R4
— preload-data-config PreloadDataType=”SYNTHEA”
— datastore-name “FhirTestDatastore”
The following example shows how to use the AWS CLI to start the import job
aws healthlake start-fhir-import-job
— input-data-config S3Uri=”s3://(Bucket Name)/(Prefix Name)/”
— datastore-id (Datastore ID)
— data-access-role-arn “arn:aws:iam::(AWS Account ID):role/(Role Name)”
— region us-east-1
2. Create, Read, Update, Delete (CRUD) operations: Manage and query data using the CreateResource, ReadResource, UpdateResource, and DeleteResource operations for 71 different FHIR resource types. These operations are all handled through an HTTP client.
The following example shows up to create a patient FHIR resource using POST.
POST /datastore/(Datastore ID)/r4/Patient/ HTTP/1.1
Host: healthlake.us-east-1.amazonaws.com
Content-Type: application/json
Authorization: AWS4-HMAC-SHA256 Credential=(Redacted)
{
“resourceType”: “Patient”,
“active”: true,
“name”: [
{
“use”: “official”,
“family”: “Doe”,
“given”: [
“Jane”
]
},
{
“use”: “usual”,
“given”: [
“Jane”
]
}
],
“gender”: “female”,
“birthDate”: “1966–09–01”
}
3. FHIR search across all data: Amazon HealthLake provides the basic FHIR search functionality, enabling users to query a Data Store based on parameters or resource IDs to navigate to specific records of interest.
The following parameters are supported in HealthLake.
· Number — Searches for a numerical value.
· Date/DateTime — Searches for a date or time reference.
· String — Searches for a sequence of characters.
· Token — Searches for a close-to-exact match against a string of characters, often against a pair of values.
· Composite — Searches for multiple parameters for a single resource type, using the AND operation.
· Quantity — Searches for a number, system, and code as values. A number is required, but system and code are optional.
· Reference — Searches for references to other FHIR resources. An example is a search for a reference to a patient within an Observation resource.
· URI — Searches for a string of characters that unambiguously identifies a particular resource.
· Special — Searches based on integrated medical NLP extensions.
The following example demonstrates how to search DocumentReferences for streptococcal diagnosis and amoxicillin medication using an HTTP client with a GET search for the following input in HTTP.
GET /datastore/(Datastore ID)/r4/DocumentReference?_lastUpdated=le2021–12–19&infer-icd10cm-entity-text-concept-score;=streptococcal|0.6&infer-rxnorm-entity-text-concept-score=Amoxicillin|0.8 HTTP/1.1
Host: healthlake.us-east-1.amazonaws.com
Content-Type: application/json
Authorization: AWS4-HMAC-SHA256 Credential= (Redacted)
4. Build ML model using Integrated medical natural language processing (NLP):
Amazon HealthLake automatically integrates with natural language processing (NLP) for the DocumentReference resource type. The integrated medical NLP output is provided as an extension to the existing DocumentReference resource. The integration involves reading the text data within the resource, and then calling the following integrated medical NLP operations: DetectEntities-V2, InferICD10-CM, and InferRxNorm. The response of each of the integrated medical NLP APIs is appended to the DocumentReference resource as an extension that is searchable. This enables users to identify patients through elements of their records that were previously buried within unstructured text. When we create a resource in HealthLake, the resource is updated with the response from the integrated medical NLP operations. These extensions follow the FHIR format for extensions with an identifying URL, and the respective value for the URL.
Reference Architecture with Amazon HealthLake
Above reference architecture shows how we can build interactive dashboard using Amazon Quicksight to search and query the data resides in Healthlake.
Advantage with Amazon HealthLake
· Healthcare providers struggle to apply intelligence to their data because it’s usually spread across numerous repositories in various formats such as clinical notes, reports and image scans. It can take months to prepare, stage and transform that data for analysis. Amazon HealthLake to quickly analyze a massive database and highlight a subset of patients who are struggling to manage their particular disease or disorder properly. The service then made recommendations on how to adjust each person’s treatment to avoid further complications.
· Amazon HealthLake can automatically understand and extract meaningful medical information from raw, disparate data, such as prescriptions, procedures, and diagnoses-revolutionizing a process that was traditionally manual, error prone, and costly.
· Interoperability ensures that health data is shared in a consistent, compatible format across multiple applications. Amazon HealthLake creates a complete, chronological view of each patient’s medical history, and structures it in the FHIR standard format to facilitate the exchange of information
References:
https://aws.amazon.com/healthlake/
https://aws.amazon.com/blogs/architecture/store-protect-optimize-your-healthcare-data-with-aws/