The Dota 2 Season is coming! After taking a break last year because of the pandemic, except for the regional online tournaments, Dota 2, DPC season is now coming back with a new format and is starting today.
For those who are not familiar, Dota 2 is the biggest title in E-Sports with the latest edition its largest tournament, The International 10, gathering the largest prize pool in all tournaments at 40 million US Dollars despite it being postponed because of the pandemic. Also, 29 of the 30 players with the highest total earning in Esports are Dota 2 professionals.
Dota 2 is a multiplayer online battle arena game played by 10 players separated into two teams and are playing to get control of the enemy base and destroy the most important structure called Ancients. Each player independently controls a character called hero, who all have unique abilities and differing styles of play.
The heroes of course are the most important part of the game. Different hero combinations and match ups gives excitement to the game and offers a variety in each match. The heroes for the opposing teams were selected from a pool of 120 unique heroes.
We might want to predict the outcome of a match based on the heroes picked alone. Of course, this is possible, and for that, we will explore the Naïve-Bayes classifier.
Naïve-Bayes is a rather simple yet effective classifier. It dwells on the assumption that the features are independent to each other and is based on Bayes Theorem. This theorem describes the probability of an event, based on prior knowledge of conditions that might be related to the event. Simply put, it describes the probability of an event A given that event B happened based on the knowledge of the probabilities of both events A and B and the conditional probability of event B given that A happened.
So, for a given class, y and a feature vector X, the probability of class y is given by:
However, since for a given feature set, each feature is assumed to be independent to each other. Note that this is not always the case, but this assumption still works most of the time. In Dota 2, for example, heroes can be picked independent of each other, however, there are hero combinations that works best with each other or teams may opt to play for heroes with better match ups against the opposing teams’ heroes.
Still, assuming that each feature is independent of each other, the probability that both will happen is equal to the product of their individual probabilities. Therefore, the probability for a class can be written as:
Since the denominator part is constant for all class, this is omitted in the calculation, making the classifier naïve and not giving exact probabilities. Classification is done by getting the class with the highest value.
In Dota 2, a match can only have 2 outcomes, either the one team win, or they lose, therefore, the class probability can also be omitted. To predict if a set of heroes will win against the opposing team, we can write the classifier mathematically as:
For a single hero, we can get the posterior probability, P(hero|win) or P(hero|loss) by its winning rate or losing rate. In other words, the number of matches it won or lost, divided by the total number of matches. Again, the total number of matches is constant for the whole training set and we can omit that to further simplify the calculations. The final classifier can then be written as:
The past patch, 7.27, was used for a very long time and several online tournaments were played in this patch. A dataset of the heroes played from official professional matches from this patch was created from Opendota API.
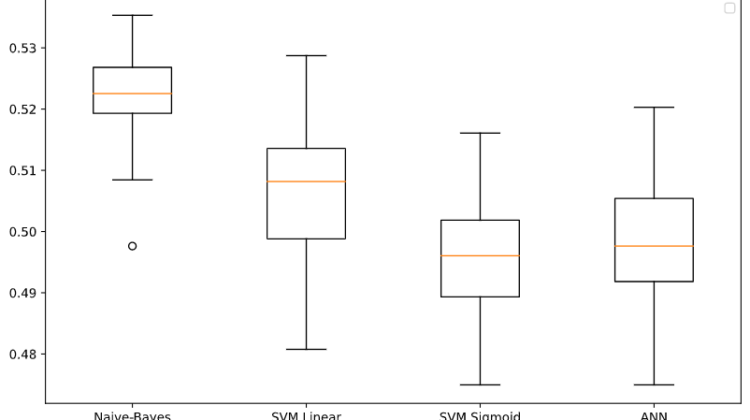
To test the performance of the classifier, the dataset is split to training and test set using a 70–30 random split. The model is trained using the training set and evaluated using the test set. This procedure is repeated 50 times to determine the performance of the classifier.
The same dataset and train-test split are used to train a linear SVM classifier and a sigmoid SVM as well. Also, an ANN with three hidden layers was trained for comparison.
In general, the Naïve-Bayes classifier performed better than the other three classifiers with a mean of 52.24% ang achieving a maximum value of about 54%. This is not a huge leap but still, better than just blindly predicting a winning team.
It must be noted though that patches have different results from each other (since usually, a patch nerfs the best heroes of the previous patch and buffs the worst performing heroes, aiming for a balanced game). In other words, the results of the previous patch are not transferable to the current patch as shown by the results of using the professional matches from patch 7.26 to predict the 7.27 matches outcome.
In conclusion, the Naïve Bayes classifier is a simple classifier that, without any other data besides the heroes used in a match, can be used to enhance your chances of predicting the outcome amidst by only a few percentages. Of course, it would not hurt to have further data that can be used in making such predictions like the performance of the teams in general, or when using certain heroes and combination of heroes and such.