Co-occurrence Based Models and Dynamic Logistic Regression.
In the previous blog, we defined embeddings and we discussed one of the popular neural architecture in Word2Vec. In this blog, we will briefly discuss yet an another famous neural architecture called Skip-gram. We will spend significant amount of time understanding other available embeddings like GloVe.
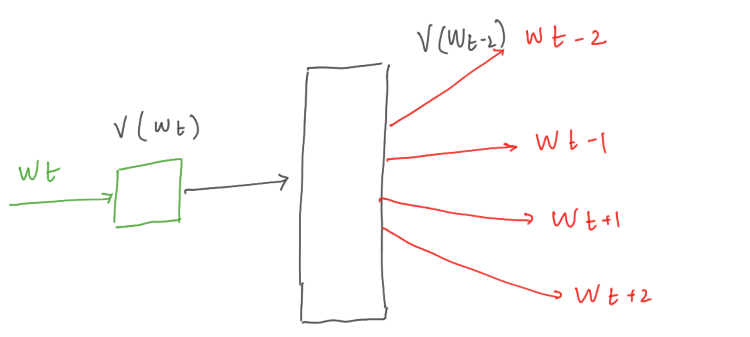
CBOW model is trained to predict a target word based on the nearby context words, the skip-gram model is trained to predict the nearby context words based on the target word. It is exactly opposite to CBOW model. For a context window c, the skip-gram model is trained to predict the c words around the target word.
The neural architecture and training of skip-gram is very similar to CBOW. So we will limit our discussion on neural architecture of skip-gram. The objective of the skip-gram model is to maximise the average log probability:
Though, word2vec have brought about great improvements and advancements in NLP, they are not without shortcomings.
- Word2vec are local-context based and generally perform poorly in capturing the statistics of the corpus.
- Inability to handle unknown or Out Of Vocabulary words: If your model hasn’t encountered a word before, it will have no idea how to interpret it or how to build a vector for it
- Word2Vec are local-context based and generally perform poorly in capturing the statistics of the corpus.
Local context based methods like Word2Vec are known to fail capturing the global statistic/structure of the corpus. There is an another school of thought that suggest global understanding of text or corpus than localised approach.
This school propound that strong association between the words can be understood by analysing their occurrence in all documents in the available corpus. This methods are referred as Co-occurrence models as the co-occurrence of words can reveal much about their semantic proximity and meaning.
We will need a measure to quantify the co-occurance of 2 words “W1”, “W2”. Pointwise Mutual Information (PMI) is very popular co-occurance measure.
p(w) is the probability of the word occurring, and p(w1,w2) is joint probability. High PMI indicate strong association between the words.
Co-occurrence methods are usually very high dimensional and require much storage. NLP engineers usually leverage dimensionality reduction techniques to handle high dimensional data. Though global co-occurrence based models succeed in capturing global statistics because of huge storage requirements these models are not able to replace the static Word2Vec embeddings.
The most widely used static embedding model besides word2vec is GloVe short for Global Vectors. The model is based on capturing global corpus statistics. This method combines both co-occurrence methods and shallow window methods. Let’s briefly understand how GloVe vectors are created.