Production ML is hard. If we can better understand the challenges in deploying ML, we can be better prepared for our next project. That’s why I enjoyed reading Challenges in Deploying Machine Learning: a Survey of Case Studies (on arXiv 18 Jan, 2021) by Paleyes, Urma, and Lawrence. It surveys papers and articles within the last 5 years relevant to the ML deployment process. To group challenges during the ML development process, the authors separated the ML workflow into 4 high level steps, from data management to model deployment. Afterwards there is a section on cross-cutting issues.
In this post, I’ll share key highlights from the paper, and supplement those key points with summaries of referenced material. We’ll talk about:
- Model reuse
- Effective collaboration between researchers and engineers
- Outlier detection for better predictions
- Handling concept drift
- End-user trust
- Adversarial attacks
This post is not a full summary of the paper but rather topics I found the most novel.
Model reuse
In software engineering code reuse can result in less code to maintain and can encourage modularity and extensibility. The idea of reuse can be applied to ML models. Let’s look at Pinterest as an example. Pinterest used image embeddings to power visual search. They used three separate embeddings specialized for three different tasks. As a result, maintenance, deployment, and versioning of the different embeddings quickly got overwhelming. As a solution, they unified embeddings under a multi-task learning framework. The result — less maintenance burden and greater performance.
To quote:
[The solution] takes advantage of correlated information in the combination of all training data from each application to generate a unified embedding that outperforms all specialized embeddings previously deployed for each product.
About the figure: Everything in the blue box is one large neural network. The circled component (circled by me) produces the universal embeddings. Both embeddings and the downstream task specific networks are optimized jointly.
A question for ML practitioners is: are there common modeling components that can be reused across ML applications? Maybe you can’t use back-propagation to optimize a common neural network layer, but you can use shared components for model explainability, outlier detection, and so on.
Effective collaboration between researchers and engineers
Paleyes mentioned that although there seems to be a clear separation of roles between ML researchers and engineers, siloed research and development can be problematic. Throwing data science research “over the wall” to an engineering team is usually considered an anti-pattern. Researchers should work with engineers to own product code since it improves both iteration speed and product quality. This is aligned with how Stitchfix structures their data team, and this article on why data scientists should be more end-to-end.
Outlier detection for better predictions
Models can generalize poorly on out-of-distribution inputs, resulting in incorrect outputs with high confidence. In production it’s important to detect outliers that could result in untrustworthy predictions.
For example, say you maintain a model that predicts whether a customer will churn, and it’s used by the customer relationship team. That team invests significant effort to save large accounts with high predicted risk of churn, and mostly ignores “healthy” accounts. There are nontrivial costs to incorrect predictions — effort spent on accounts that don’t need the attention (and could be better spent elsewhere), or churn on unhealthy accounts that were neglected. At some point your model gets an outlier, an account with characteristics wildly different from the training data. Instead of letting the model confidently spit out a prediction, it may be better to display a message that says the account is an outlier and warrants further investigation, from both data science and the customer relationship team. The culprit could actually be an upstream data issue.
Outlier detection in itself can be hard, as there is often a lack of labelled outliers. Paleyes referenced a paper from Seldon Technologies, which mentioned the detector can be pre-trained or updated online. For the former the detector is deployed as a separate model, and becomes another model to evolve and maintain. The latter can be deployed as a stateful application.
Handling concept drift
When the world changes, your model of the world can become out-of-date and inaccurate. This is called concept drift in ML, and is defined as a shift in the joint distribution P(X, y). Usually X is the training data and y is the target variable. Real-world analogies of failing to learn from concept drift are companies that go under because they don’t adapt to changing markets, and older folk who make Seinfeld references in an attempt to connect with Gen Z (it’s not gonna work).
In ML, concept drift can also arise when the data collection method changes — the world hasn’t changed, but it looks like it did from the model’s perspective. Maybe data processing code changed upstream, or an IoT sensor was upgraded.
Paleyes referenced a paper that explored the effect of drift on AutoML algorithms. The authors of the referenced paper used both real-world and synthetic datasets with concept drift. They defined different adaptation strategies to adapt models to detected drift, and compared results for each combination of AutoML system, adaptation strategy, and dataset.
In the above figure, the first 4 strategies define what to do when drift is detected. For example, Detect and Increment trains the AutoML model incrementally on the most recent batches of data. The last strategy is a baseline with no retraining. I’ll defer to the paper for more in-depth descriptions of each strategy. Below are model accuracy results for each adaptation strategy on real-world data from IMDB.
In the figure, The baseline of no retraining is the yellow line. It seems the Detect and Increment strategy, in magenta, works best on this dataset, but is sometimes worse than the Periodic Restart strategy.
A conclusion from the paper is the best adaptation strategy depends on both the AutoML system and the dataset. Basically, no free lunch and you’ll have to figure out what works best for your problem.
End-user trust
As a data scientist you may have great confidence in your model, but end-users may be wary of the model predictions. Much of the emphasis on building trust with end-users has been around model interpretability, but Paleyes argues interpretability is only one piece of the puzzle. You also need to build strong communication channels with end-users, develop the system transparently, and design a user interface catered to your audience.
As an example, the authors of a referenced paper describe their ML system design for the Atlanta Fire Rescue Department (AFRD). The project had 2 main goals:
- Identify commercial properties eligible for fire inspection. AFRD did not have an accurate list of properties since the data was siloed in various organizations.
- Develop a model to predict fire risk for identified properties.
It was clear the authors worked closely with AFRD and took their needs into consideration. One example is how they translated predicted risk probabilities into risk categories of low, medium, and high:
risk categorizations were intended to assign a manageable amount of medium risk (N = 402) and high risk properties (N = 69) for AFRD to prioritize.
The authors also worked with AFRD to design a user interface to aid decision making. They learned that along with fire risk scores, AFRD wanted specific information on properties and the political subdivisions of the city. The end result is an interface with the ability to filter and overlay information, where risk score is one part of a larger offering.
Adversarial attacks
One adversarial attack is data poisoning, where attackers try to corrupt the training data, resulting in model predictions they can take advantage of. A referenced paper explores the effect of data poisoning on linear regression models (like OLS and LASSO). One evaluation dataset involves healthcare patient data. The Model’s goal is to correctly predict the dosage for a specific drug. A data poisoning rate of 8% resulted in incorrect dosage for half the patients! ML practitioners in high-risk fields like cybersecurity and healthcare need to take extra care to guard against data poisoning attacks.
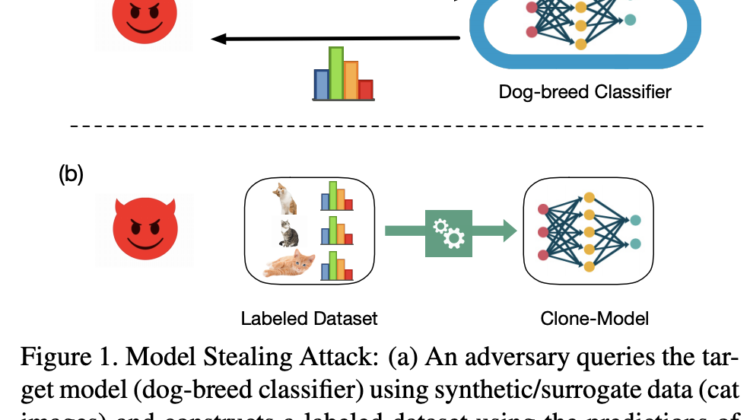
Another discussed adversarial attack is model stealing, illustrated below.
Your model endpoint essentially becomes the adversary’s Mechanical Turk. The adversary can steal your intellectual property, and with less effort than you put in to train your amazing model. The survey paper noted that in some cases, it really doesn’t take that many queries to reconstruct a similar model. It’s something to pay attention to if you plan to expose your model via API.
In summary we discussed:
- Model reuse
- Effective collaboration between researchers and engineers
- Outlier detection for better predictions
- Handling concept drift
- End-user trust
- Adversarial attacks
I hope some of these topics better prepare you for your next ML project. I know I will think more about model reuse and concept drift. Please reach out if you have related papers to recommend!
- Andrei Paleyes, Raoul-Gabriel Urma, Neil D. Lawrence: “Challenges in Deploying Machine Learning: a Survey of Case Studies”, 2020; arXiv:2011.09926.
- Andrew Zhai, Hao-Yu Wu, Eric Tzeng, Dong Huk Park, Charles Rosenberg: “Learning a Unified Embedding for Visual Search at Pinterest”, 2019; arXiv:1908.01707.
- Janis Klaise, Arnaud Van Looveren, Clive Cox, Giovanni Vacanti, Alexandru Coca: “Monitoring and explainability of models in production”, 2020; arXiv:2007.06299.
- Bilge Celik, Joaquin Vanschoren: “Adaptation Strategies for Automated Machine Learning on Evolving Data”, 2020; arXiv:2006.06480.
- Madaio, M., Chen, S.-T., Haimson, O. L., Zhang, W., Cheng, X., Hinds-Aldrich, M., Chau, D. H., & Dilkina, B. (2016, August 13). Firebird. Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. KDD ’16: The 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. https://doi.org/10.1145/2939672.2939682
- Matthew Jagielski, Alina Oprea, Battista Biggio, Chang Liu, Cristina Nita-Rotaru, Bo Li: “Manipulating Machine Learning: Poisoning Attacks and Countermeasures for Regression Learning”, 2018; arXiv:1804.00308.
- Sanjay Kariyappa, Moinuddin K Qureshi: “Defending Against Model Stealing Attacks with Adaptive Misinformation”, 2019; arXiv:1911.07100.