There are few metrics using which we can evaluate a logistic regression model,
1) AIC ( Akaike Information Criteria)
2) Confusion matrix
3) ROC curve
4) Null deviance and residual deviance
To understand this topics will take example of one logistic regression model and its results
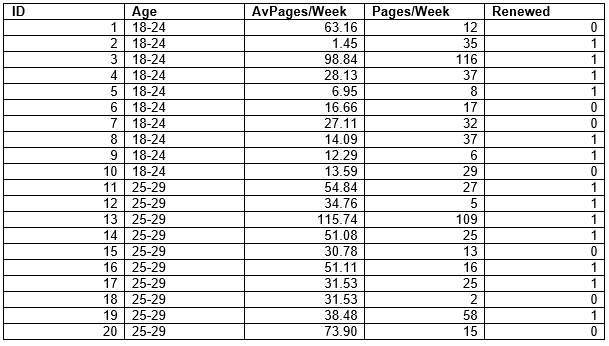
Dataset
Now to check and compare those result will change some data’s of this dataset
Main AIM of AIC is to compare different models and find out best fitting model from the given different models. In-order do to so we have to create a set of different models using different parameters depend on the data. After that we can use AIC to compare those models.
Low AIC means model is good so by comparing different models we can select best fitting model. If 2 models have same AIC than one with fewer parameters can be taken as better-fit model. AIC uses concept of maximum likelihood. AIC is calculated using following formula,
AIC = 2p — 2 (log-likelihood)
Here p is number of parameters and log-likelihood is a measure of model fit. The higher the number the better the fit.
And here as you can see AIC is 26.367 for final model
Now after changing parameters 18,19,20 will get,
Here value of AIC is 34.404 which is bigger compare to our previous model means this model is not good compare to our previous model.
Confusion matrix is method used to summarize classification algorithm on set of test data for which the true values are previously known. Sometime it also refer as error matrix.
Confusion matrix will look like this,
P = Positive; N = Negative; TP = True Positive; FP = False Positive; TN = True Negative; FN = False Negative.
True positive : TP means model predicted yes and correct answer for that is also yes
True negative : TN means model predicted no and correct answer for that is also no.
False positive : FP means model predicted yes but actual answer is no
False negative : FN means model predicted no but actual answer is yes
So there is list of rate calculated using this matrix
1) Accuracy = (TP+TN/Total ) tells about overall how classifier Is correct.
2) True positive rate : TP/(actual yes) it says about how much time yes is predicted correctly. It is also called as “sensitivity” or “recall”
3) False positive rate : FP/(actual number) it says about how much time yes is predicted when actual answer is no
4) True negative rate : TN/(actual number) it says about how much time no is predicted correctly and actual answer is also no. it is also known as “specificity”
5) Misclassification rate : (FP+FN)/(Total) it is also known as error rate and tells about how often our model is wrong
6) Precision : ( TP/ (predicted yes) ) if it predict yes then how often it is correct ?
7) Prevalence : (actual yes /total) how often yes condition really/actually occurs.
Value of actual data is
Now by computing confusion matrix our model will get
Here we can see that our model is 78.33% correct in predicting. Now let us find the same for our 2nd model where I have changed value of parameter 18, 19,20,
Actual data will be,
And confusion matrix will be,
It is clearly observed that first model is more accurate compare to second.
ROC- Receiver operating characteristic curve will help to summarize model’s performance by calculating trade-offs between TP rate (sensitivity) and FN rate (1-specificity) it will plot this 2 parameters. To classify this terms AUC (Area under the curve) is introduce which gives summary of ROC curve.
The higher the AUC, the better the performance of classifier. ROC curve may look like this,
AUC is classified on follwing basis, If AUC = 1, then the classifier is able to perfectly distinguish between all the Positive and the Negative class points correctly
1) If AUC =0 then classifier is predicting all the positive as negative and negative as positive.
2) If 0.5< AUC < 1 means classifier will distinguish the positive class value from negative class value because it is finding more number of TP and TN compare to FP and FN.
3) If AUC = 0.5 it means classifier is not able to distinguish between positive and negative values.
So we can conclude that higher the value of AUC better its ability to distinguish between positive and negative classes.
Now let’s find value of AUC for our both model and compare it, ROC for first model is,
ROC for second model is,
Here we can see that value of AUC in first model is 0.899 while in second it is 0.510 which means our first model is good compare to our 2nd model and, in first model it is predicting some of negative value as positive while in 2nd it is very close to 0.5 means our classifier is not able to distinguish between positive and negative value.
Deviance is measure of goodness of fit of a generalized linear model. Specifically null deviance represents difference between a model with no or 1 predictor and saturated model. It will provide a base model through which we can compare other predictor models. So mathematically we can say
Saturated model assumes that we have n parameters to estimate.
Null deviance = 2(LL(saturated model))-LL(null model)
If we get value of Null Deviance very small means our model is explaining our data set very well.
· Residual deviance
While residual deviance tells about difference between proposed model and saturated model.
Proposed model assumes that we have p parameters + intercept terms to be estimate.
So mathematically we can say,
Residual Deviance = 2(LL(saturated model)) — LL((proposed model))
Same as null deviance if we get value of residual deviance very small then our model is proper for given dataset.
Summary for proposed model is,
Now if we count Residual Deviance then it is,
=-18.367+5.4975 = -12.8695
Now for second model
Residual Deviance = -26.404 + 5.4975 = -20.9065 if we ignore sign then value for first models is less than value of second which means our 1st model is better fit compare to second model.
Last we can say that it depends on model developer which method he wants to use and also depend on our type of data.