Muchos habréis leído el termino Machine Learning en las noticias, ya que parece que es la palabra de moda. Habréis visto que las empresas están empezando a incorporarlo en sus proyectos, y es que el Machine Learning ha venido para quedarse. ¿Pero qué es exactamente? En este post, explicaremos qué es a alto nivel y así podrás tener una idea de sus numerosas aplicaciones.
El Machine Learning o Aprendizaje Automático tiene como objetivo crear algoritmos que aprenden de los datos, para poder obtener valor a través de ellos. La idea es probar diferentes combinaciones matemáticas, para poder descifrar con un alta precisión, la relación que tienen todos los datos entre sí.
La idea general del Aprendizaje Automático, es la de crear programas que puedan automatizar las tareas complejas que realiza una persona. Por ejemplo, que puedan ver una imagen y diferenciar automáticamente entre gatos y perros. Esta tarea puede no parecer muy impresionante, pero fue foco de la investigación de este campo durante muchos años.
El Aprendizaje Automático se puede dividir en un subconjunto de bloques en función del tipo de dato con el que se trabaja. Esto lo veremos a continuación.
¿Qué entendemos por aprendizaje supervisado? Son aquellos algoritmos que deben de ser entrenados con datos etiquetados. El ejemplo anterior de diferenciar entre perros y gatos es un ejemplo de problema de Aprendizaje Supervisado, ya que se los datos proporcionados para el algoritmo deberían ser imágenes con etiquetas como perro o gato, en su respectivo caso. Por lo que si entrenamos un algoritmo con imágenes de perros, y de gatos, la idea es que si le enseñáramos una imagen de un perro que no ha visto previamente, debería de poder clasificarla correctamente.
Hemos estado hablando de problemas de clasificación, pero el aprendizaje supervisado también engloba problemas de regresión. La diferencia entre clasificación y regresión consiste en que en la clasificación se intenta predecir una variable categórica, es decir, algo como perro o gato, mientras que en la regresión, se pretende predecir un valor numérico. Para la regresión podemos imaginar el problema de la predicción del valor de las acciones en bolsa.
A diferencia del Aprendizaje Supervisado, en el Aprendizaje No Supervisado los datos carecen de una etiqueta, por lo que su objetivo no consiste en predecir su valor correspondiente, sino en ver relaciones en los datos existentes para poder inferir si existe algún tipo de nexo entre ellos.
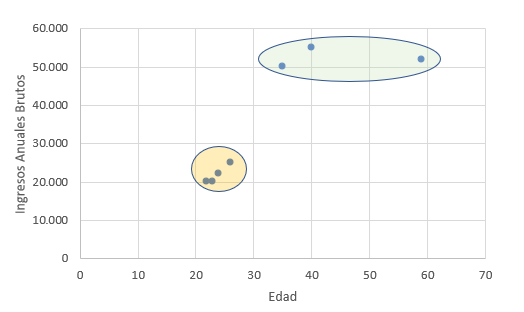
Algunos tipos problemas de Aprendizaje No Supervisado serían, la agrupación de datos (Clustering en inglés), en la que a partir de unos datos sin etiquetas se pretende separar los datos en grupos que tienen una relación entre ellos. Por ejemplo, imaginemos que tenemos datos de personas, como su edad y sus ingresos anuales brutos. Si tuviésemos una empresa de electrodomésticos y quisiéramos llevar cabo una campaña para promocionar una nueva gama alta de neveras, nos interesaría hacer más enfoque en las personas con un mayor poder adquisitivo. Aquí es donde entraría en juego el Clustering.
Aquí podemos ver que tendríamos dos grupos, uno de gente joven con ingresos bajos y otro de gente mayor de 35 años, con ingresos más elevados, por lo que en esta campaña nos interesaría hacer más hincapié en aquellos personas mayores de 35.
Otras aplicaciones del Aprendizaje No Supervisado sería la Detección de Anomalías, con aplicación directa en campos como la detección de fraude, o la Reducción de Dimensionalidad, utilizada cuando tenemos unos datos con unas variables, pero queremos reducir su tamaño, quedándonos solo con aquellos valores qué más pueden aportarnos.
Esta es otra de las áreas del Machine Learning que más protagonismo está cogiendo en los últimos años. Consiste en entrenar un agente en un entorno simulado mediante funciones de recompensa, donde se premia al agente cuando consigue hacer algo bien y se le castiga cuando lo ha hecho mal. Su aplicación más directa es en el campo de los videojuegos, ya que es muy sencillo entrenar un agente en este tipo de entornos, ya que una simulación consistiría simplemente en llevar a cabo una partida del juego.
En 2016, AlphaGo, un agente creado por miembros del equipo Google Deepmind, venció a uno de los mejores jugadores del mundo en el juego Go, considerado como un juego de extrema dificultad computacionalmente hablando, debido a la increíble combinatoria de posibles pasos a realizar en cada turno.
El campo de la Visión por Computador engloba todas aquellas tareas que tienen que ver con las imágenes y vídeos. Su objetivo es automatizar aquellos problemas que los humanos podemos realizar casi perfectamente con las imágenes, como poder ver una imagen e identificar correctamente de qué se trata, así como de describir con exactitud donde se encuentra en la imagen un objeto y de poder dar una descripción acertada del contenido de una imagen.
El ejemplo de diferenciar entre perros y gatos, se incluiría dentro de la clasificación de imágenes de este campo.
La Visión por Computador, no pertenece al campo del Machine Learning, pero si hereda técnicas que se utilizar en él, ya que han permitido resolver con una gran mejoría muchos de los problemas de los que hemos hablado. Esto se debe en gran parte al uso de técnicas como las Redes Neuronales, que han mostrado resultados del estado del arte (los mejores hasta el momento), en diversas tareas.
Al igual que el campo de la Visión por Computador, el campo del Procesamiento de Lenguaje Natural, hereda técnicas del Machine Learning, pero no pertenece a un subconjunto de este.
Este campo lleva a cabo la investigación de todos aquellos problemas que tienen que ver con texto y su entendimiento, como la traducción de textos a otros idiomas, la identificación de tópicos en un texto o el desarrollo de sistemas conversacionales (chatbots).
En este post hemos hablado de los distintos campos del Machine Learning, así como de algunas de sus posibles aplicaciones. No hemos entrado en detalle, ya que la idea era solo tener un conocimiento general de los diferentes campos en los que se divide. En futuros posts ya entraremos más en detalle en cada uno.
Espero que les haya gustado. Si tienen cualquier duda, no duden en dejarla en los comentarios.
Si quieres leer más posts como este, entra en nuestro blog themachinelearners.