In this Blog I will be writing about a very famous classification as well as regression ML algorithm, that is, Random Forest
Here I will explain about what is random forest, why we use it, Introduction to ensemble method, Random Forest analogy, How to use Random Forest, Applications of Random Forest, Advantages/Disadvantages also I will provide link to my Jupyter notebook where I have implemented Random Forest algorithm, you check that for reference.
So without any further due lets get started.
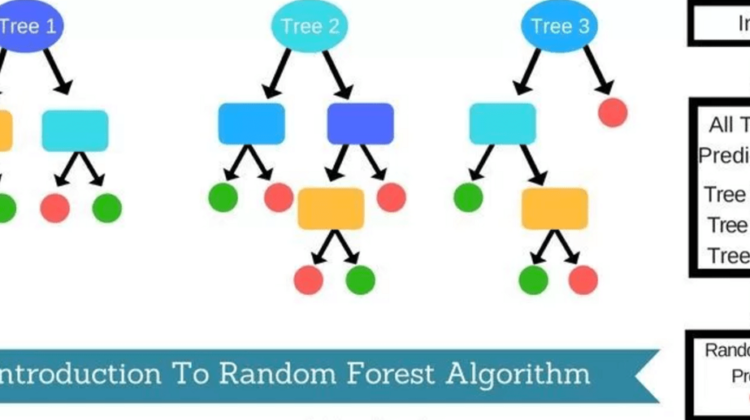
A random forest consists of multiple random decision trees. Two types of randomnesses are built into the trees. First, each tree is built on a random sample from the original data. Second, at each tree node, a subset of features are randomly selected to generate the best split.
To answer this question, we will suggest some of its advantages and important features which will clear your mind why use the RF Algorithm in machine learning.
- Random forest algorithm can be used for both classifications and regression task.
- It provides higher accuracy through cross validation.
- Random forest classifier will handle the missing values and maintain the accuracy of a large proportion of data.
- If there are more trees, it won’t allow over-fitting trees in the model.
- It has the power to handle a large data set with higher dimensionality.
What is Ensemble Learning?
Ensemble learning, in general, is a model that makes predictions based on a number of different models. By combining individual models, the ensemble model tends to be more flexible (less bias) and less data-sensitive (less variance).
There are two types of Ensemble Method —
- Bagging: Training a bunch of individual models in a parallel way. Each model is trained by a random subset of the data
- Boosting: Training a bunch of individual models in a sequential way. Each individual model learns from mistakes made by the previous model.
The following are the basic steps involved in performing the random forest algorithm:
- Pick N random records from the dataset.
- Build a decision tree based on these N records.
- Choose the number of trees you want in your algorithm and repeat steps 1 and 2.
- In case of a regression problem, for a new record, each tree in the forest predicts a value for Y (output). The final value can be calculated by taking the average of all the values predicted by all the trees in forest. Or, in case of a classification problem, each tree in the forest predicts the category to which the new record belongs. Finally, the new record is assigned to the category that wins the majority vote.
Problem Definition
The task here is to predict whether a bank currency note is authentic or not based on four attributes i.e. variance of the image wavelet transformed image, skewness, entropy, and curtosis of the image.
Solution
This is a binary classification problem and we will use a random forest classifier to solve this problem. Steps followed to solve this problem will be similar to the steps performed for regression.
1. Import Libraries
import pandas as pd
import numpy as np
2. Importing Dataset
The dataset can be downloaded from the following link:
The following code imports the dataset and loads it:
dataset = pd.read_csv("../path/bill_authentication.csv")dataset.head()
As was the case with regression dataset, values in this dataset are not very well scaled. The dataset will be scaled before training the algorithm.
3. Preparing Data For Training
The following code divides data into attributes and labels:
X = dataset.iloc[:, 0:4].values
y = dataset.iloc[:, 4].values
The following code divides data into training and testing sets:
from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
4. Feature Scaling
As with before, feature scaling works the same way:
# Feature Scaling
from sklearn.preprocessing import StandardScalersc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
5. Training the Algorithm
And again, now that we have scaled our dataset, we can train our random forests to solve this classification problem. To do so, execute the following code:
from sklearn.ensemble import RandomForestRegressorregressor = RandomForestRegressor(n_estimators=20, random_state=0)
regressor.fit(X_train, y_train)
y_pred = regressor.predict(X_test)
In case of regression we used the RandomForestRegressor class of the sklearn.ensemble library. For classification, we will RandomForestClassifier class of the sklearn.ensemble library. RandomForestClassifier class also takes n_estimators as a parameter. Like before, this parameter defines the number of trees in our random forest. We will start with 20 trees again. You can find details for all of the parameters of RandomForestClassifier here.
6. Evaluating the Algorithm
For classification problems the metrics used to evaluate an algorithm are accuracy, confusion matrix, precision recall, and F1 values. Execute the following script to find these values:
from sklearn.metrics import classification_report, confusion_matrix, accuracy_scoreprint(confusion_matrix(y_test,y_pred))
print(classification_report(y_test,y_pred))
print(accuracy_score(y_test, y_pred))
The output will look something like this:
[[155 2]
1 117]]
precision recall f1-score support 0 0.99 0.99 0.99 157
1 0.98 0.99 0.99 118 avg / total 0.99 0.99 0.99 2750.989090909091
The accuracy achieved for by our random forest classifier with 20 trees is 98.90%. Unlike before, changing the number of estimators for this problem didn’t significantly improve the results, as shown in the following chart. Here the X-axis contains the number of estimators while the Y-axis shows the accuracy.
98.90% is a pretty good accuracy, so there isn’t much point in increasing our number of estimators anyway. We can see that increasing the number of estimators did not further improve the accuracy.
Check below link as well. Here’s my explained Implementation of Random Forest Algorithm on Jupyter Notebook.
The random forest also gives you a good feature that can be used to compute less important and most important features. Sklearn has given you an extra feature with the model that can show you the contribution of each individual feature in prediction. It automatically calculates the appropriate score of independent attributes in the training part. And then it is scaled down so that the sum of all the scores comes out to be 1.
The score will help you to decide the importance of independent features and then you can drop the features that have least importance while building the model.
Random forests make use of Gini importance or MDI (Mean decrease impurity) to compute the importance of each attribute. The amount of total decrease in node impurity is also called Gini importance. This is the method through which accuracy or model fit decreases when there is a drop of the feature. More appropriate the feature is if large is the decrease. Hence, the mean decrease is called the significant parameter of feature selection.
There are many different applications where a random forest is used and gives good reliable results that include e-commerce, banking, medicine, etc. A few of the examples are discussed below:
- In the stock market, a random forest algorithm can be used to check about the stock trends and contemplate loss and profit
- In banking, the random forest can be used to compute the loyal customers that means which customer will default and which will not. Fraud customers or customers having a bad record with the bank.
- Calculations of the correct mixture of compounds in medicine or whether identifying any sort of disease using the patient’s medical records.
- The random forest can be used for recommending products in e-commerce.
- It overcomes the problem of overfitting.
- It is fast and can deal with missing values data as well.
- It is flexible and gives high accuracy.
- Can be used for both classifications as well as regression tasks.
- Using random forest you can compute the relative feature importance.
- It can give good accuracy even if the higher volume of data is missing.
- Random forest is a complex algorithm that is not easy to interpret.
- Complexity is large.
- Predictions given by random forest takes many times if we compare it to other algorithms
- Higher computational resources are required to use a random forest algorithm.