This article is based on a talk I gave with Hannes Hapke at PyData Global, November 2020.
Deploying your machine learning model to a production system is a critical time: your model begins to make decisions that affect real people. This is the perfect moment to think about the many aspects that make up responsible machine learning: checking for harmful bias in predictions, being able to explain the model’s predictions, preserving the privacy of users, and tracking the model’s lineage for auditing. While you should consider all these aspects during the experimental phase of a machine learning project, deploying a model to production can be the most important time for them. It’s at this point that your model’s predictions reach real people — not just arrays named X_test and y_test — and harmful impacts may become apparent.
The tools for dealing with these issues of fairness, explainability, privacy and auditability are at different levels of maturity. In this blog post, we’ll give an overview of the available tools in the TensorFlow ecosystem to help with these issues, and show how they can be integrated into a production pipeline.
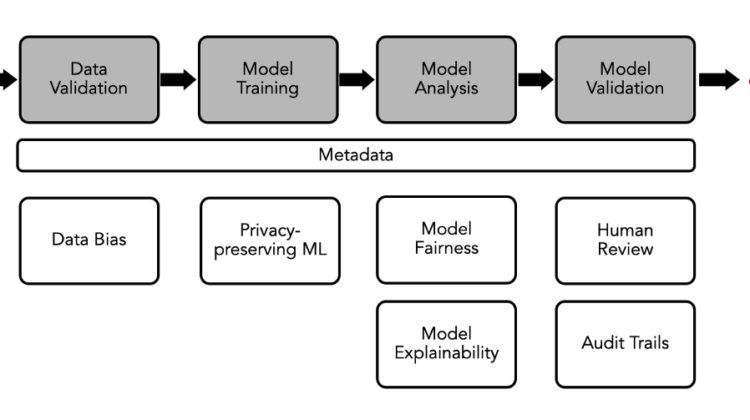
For a more comprehensive overview of all the steps in a machine learning pipeline, please see “Building Machine Learning Pipelines” (O’Reilly Media, 2020). Here we’ll keep it simple and say that a pipeline contains the following steps, as shown in the image at the top:
- Ingest some data into the pipeline
- Validate that the data is what we expect
- Train a model
- Analyze the model’s performance
- Validate the model
- Deploy the model to production
A machine learning pipeline should be standardized, scalable and reproducible. We feel that (at the time of writing) TensorFlow Extended (TFX) offers the best and most comprehensive open source method for building great pipelines. Most articles on TFX focus on setting up your pipeline, or deployment efficiency, or pipeline orchestrators, but here we want to concentrate on how TFX pipelines can enable responsible ML.
The first point in our pipeline we will consider is data on its way into our model, at the data validation step. Here we can check whether our training data contains harmful biases, and we can stop the pipeline if such biases are found. There are a couple of questions we want to answer here:
- Is my model reinforcing some harmful human bias? For example, in the case of Amazon’s hiring tool that was found to be biased against women, the model saw more information from male candidates than female candidates. This reinforced the gender disparity in hiring for tech roles.
- Is my dataset representative of my target users? This is often more of a model performance question, but we want everyone to be getting a good experience from the model we are putting into production.
TensorFlow Data Validation (TFDV) can help us answer these questions. TFDV is a visualization tool that plugs directly into our TFX pipeline, and we can use it to visualize the statistics of our features and the distribution of our input data into the model. In the example above we explore the categorical feature that is the US state, and we can see that we have a lot more data from California than from anywhere else. Perhaps this is acceptable for our product, but it might bias our model towards the preferences of people from California.
TFDV also uses a schema to ensure that the data entering the model fits the parameters we define, which allows us to stop biased data entering the model. If we’re aware of something that can reinforce a harmful real-world bias, we can set parameters for this data in TFDV. Then, if our input data is outside these parameters, the pipeline will stop at this point and the model will not be trained. For example, we could specify in our schema that there should be the same number of training examples from all 50 US states.
Privacy is an extremely important topic for production machine learning systems. There are a number of different options for privacy-preserving machine learning — differential privacy, encrypted ML, and federated learning, to name a few — and we’ve discussed these in a previous post. But right now they don’t integrate easily into production ML systems, and unfortunately this includes our TFX pipeline. However, of the options explored so far, differential privacy is the most mature, and in some use cases it can fit into the model training step in our pipeline. If you haven’t come across differential privacy before, Udacity’s “Secure and Private AI” course gives a great introduction. There are many different implementations of differential privacy, but all of them involve some randomization that masks an individual person’s data.
TensorFlow Privacy brings differential privacy to the TensorFlow ecosystem. It adds two hyperparameters to a model: gradient clipping (to ensure the gradients do not overfit to one person’s data) and the addition of some random noise into the gradient descent algorithm. It protects the model against being affected by outliers that can be linked back to an individual. The library also contains functions for easily measuring epsilon, a parameter in differential privacy that measures how including or excluding any particular point in the training data is likely to change the probability that we learn any particular set of parameters. Lower values of epsilon ensure greater privacy, but result in noisier models, whereas higher values of epsilon may give you greater results at the risk of exposing your users’ personal data. This gives us a privacy/accuracy tradeoff — as we decrease epsilon, the accuracy can decrease. In our experience it’s often not linear: you get to a certain value of epsilon, then the accuracy decreases dramatically. We are only giving greater privacy to users when the value of epsilon is low.
After our model is trained, the next step in the pipeline is to analyze its performance. This is the appropriate point to consider whether the predictions made by our model are fair to all groups of users. First, we need to define what we mean by fairness. A couple of common definitions include:
- Demographic parity: Decisions are made by the model at the same rate for all groups. For example, men and women would be approved for a loan at the same rate.
- Equal accuracy: Some metrics such as accuracy or precision are equal for all groups. For example, a facial recognition system should be as accurate for dark-skinned women as it is for light-skinned men.
A high-profile example of an unfair model in the real world was highlighted by the Gender Shades project in 2018, which found that the accuracy of commercial gender prediction algorithms was very different across different groups, with the worst performance for females with darker skin. The companies did improve those models after this study highlighted these problems, but we should aim to spot these harmful issues before we deploy our models.
One tool that helps us with model fairness is TensorFlow Model Analysis, shown in the image above. This is another visualization tool that plugs directly into our TFX pipeline. The key feature that we use is the tool’s ability to slice our analyses on different categories, and this is absolutely crucial for checking whether our model’s predictions are fair — regardless of the definition of fairness that we use.
We can also use Fairness Indicators, another tool from Google, to visualize and analyze the model we trained in our TFX pipeline. We can view it as a standalone visualization, or more preferably, as a TensorBoard plugin. The ability to view metrics sliced on features at a variety of decision thresholds — a decision threshold is the probability score where we draw the boundary between classes for a classification model — is a particularly useful feature of Fairness Indicators. This allows us to potentially change the decision threshold to one that gives us more fair predictions from our model.
Model explainability is also part of the model analysis step in our pipeline. We make a distinction here between interpretable models (where a human can follow the whole path through a model) and explainable models (where we get partial insight into why a model made its predictions), and focus on explainability. This is a big topic, with lots of active research on the subject. It isn’t something we can automate as part of our pipeline because, by definition, the explanations need to be shown to people. These explanations can help machine learning engineers audit a model, they can help a data scientist debug problems with their model, and they can help build trust in the model by explaining predictions to users.
For a TFX pipeline, the What-If Tool is a great solution that integrates smoothly. It lets us dig deeper into our model’s predictions both overall and at the level of the individual data point. Two of the most useful features are counterfactuals and partial dependence plots. For any given training example, counterfactuals show the nearest neighbor (where all the features are as similar as possible) where the model predicts a different class. This helps us see how each feature impacts the model’s prediction for the particular training example.
Partial dependence plots (PDPs) show us how each feature impacts the predictions of the model. The PDP shows us the shape of this dependence: whether it is linear, monotonic, or more complex. In the example above we can see that the hours per week feature gives a big change in inference score, but the education category does not. PDPs contain an important assumption: that all features are independent of each other. For most datasets, especially those that are complex enough to need a neural network model to make accurate predictions, this is not a good assumption. These plots should therefore be approached with caution: they can give you an indication of what your model is doing, but they do not give you a complete explanation.
When talking about machine learning pipelines, the focus is often on automation, but it’s critical that a human review every model before it gets deployed, using all of the visualization tools we described above to check for the subtle ways that a model could cause harm to people. We can add a component to our pipeline that alerts a human reviewer via Slack or some other messaging service, as shown in the image above. The reviewer can then approve the model if everything is ok, or reject it if they spot a potential problem. Ideally, a diverse set of people should review the model. The pipeline components and the visualization tools make it easy for the reviewers to get the information they need to make a decision.
In a TFX pipeline, all artifacts (such as models or datasets) are tracked using metadata. This opens up some powerful possibilities for us around audit trails, reproducibility and much more. It also powers many of the tools we have described above. Every time a TFX component carries out some action, such as training a model, it writes the details to a consistent metadata store. This means we can keep track of all the artifacts that went into a single model prediction, and we can get an audit trail all the way back to the raw data.
The metadata (in combination with the training data and other artifacts) also means that the pipeline is reproducible. References to all the actions that have been taken in the pipeline, from data ingestion through feature engineering to model training, are tracked and recorded in the metadata store. So the pipeline can be rerun to produce the exact same model if there are any questions around a prediction that it makes. We can also use this metadata to generate model cards that help us show the limitations of a model.
The next time you train a fantastic, accurate, ground-breaking model, we encourage you to pause before you push it to production. Could your training data be biased? Could you use privacy-preserving machine learning to increase your users’ privacy? Are your model’s predictions fair? Can you trace back the predictions if there is a problem with them? Take a moment to consider these questions before you deploy your model.
Right now, there isn’t a standard method for putting a machine learning model into production. As we develop our own workflows, we should make certain we consider the potential harms our models can cause, and ensure that the responsible ML methods described here are part of our deployment process. This isn’t just an opportunity for an individual to do this, it is an opportunity for the community at large to ensure that the tools and standards that do come about follow these best practices. It’s natural for us to want to automate most of the steps in our pipeline, but we must leave room for humans in the loop.
Thank you to Robert Reed, Chris Ismael, Hannes Hapke and the rest of the Concur Labs team for their help with this post!