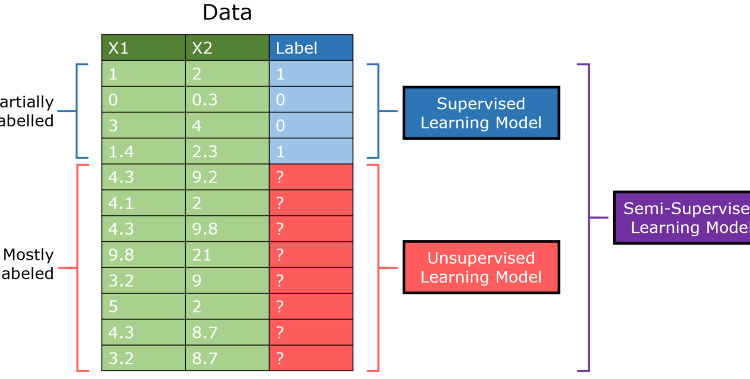
In order to understand semi-supervised learning, we should understand supervised and unsupervised learning first.
A supervised learning algorithm learns from labeled training data, helps you to predict outcomes for unforeseen data.
An unsupervised learning algorithm learns patterns in unlabeled data.
Semi-supervised machine learning is a combination of supervised and unsupervised machine learning methods. Semi-supervised learning is an approach to machine learning that combines a small amount of labeled data with a large amount of unlabeled data during training. Semi-supervised learning falls between unsupervised learning (with no labeled training data) and supervised learning (with only labeled training data). It is a special instance of weak supervision.
How semi-supervised learning works?
- Train the model with a small amount of labeled training data just like you would in supervised learning until it gives you good results.
- Then use it with the unlabeled training dataset to predict the outputs, which are pseudo labels since they may not be quite accurate.
- Link the labels from the labeled training data with the pseudo labels created in the previous step.
- Link the data inputs in the labeled training data with the inputs in the unlabeled data.
- Then, train the model the same way as you did with the labeled set in the beginning in order to decrease the error and improve the model’s accuracy.
Semi-supervised learning with clustering and classification
One way to do semi-supervised learning is to combine clustering and classification algorithms. Clustering algorithms are unsupervised machine learning techniques that group data together based on their similarities. The clustering model will help us find the most relevant samples in our data set. We can then label those and use them to train our supervised machine learning model for the classification task.
Another way to approach semi-supervised learning is including semi-supervised support vectormachines(S3VM). The general idea behind S3VM is that, you have a training data set composed of labeled and unlabeled samples. S3VM uses the information from the labeled data set to calculate the class of the unlabeled data, and then uses this new information to further refine the training data set.
An alternative approach is to train a machine learning model on the labeled portion of your data set, then using the same model to generate labels for the unlabeled portion of your data set. You can then use the complete data set to train an new model.
Applications of Semi-Supervised Learning
- Speech Analysis: Since labeling of audio files is a very intensive task, Semi-Supervised learning is a very natural approach to solve this problem.
- Internet Content Classification: Labeling each webpage is an impractical and unfeasible process and thus uses Semi-Supervised learning algorithms. Even the Google search algorithm uses a variant of Semi-Supervised learning to rank the relevance of a webpage for a given query.
- Protein Sequence Classification: Since DNA strands are typically very large in size, the rise of Semi-Supervised learning has been imminent in this field.