ARTICLE
This article delves into using shallow transfer learning to improve your NLP models.
___________________________________________________________
Take 37% off Transfer Learning for Natural Language Processing by entering fccazunre into the discount code box at checkout at manning.com.
___________________________________________________________
Semi-supervised Learning with Pretrained Word Embeddings
The concept of word embeddings is central to the field of NLP. It is a name given to a collection of techniques which produce a set of vectors of real numbers for each word that needs to be analyzed. A major consideration in word embedding design is the dimension of the vector generated. Bigger vectors generally can achieve better representation capability of words within a language and thereby better performance on many tasks, while naturally being more expensive computationally. Picking the optimal dimension represents striking a balance between these competing factors, and has often been done empirically, although some recent approaches argue for a more thorough theoretical optimization approach[1].
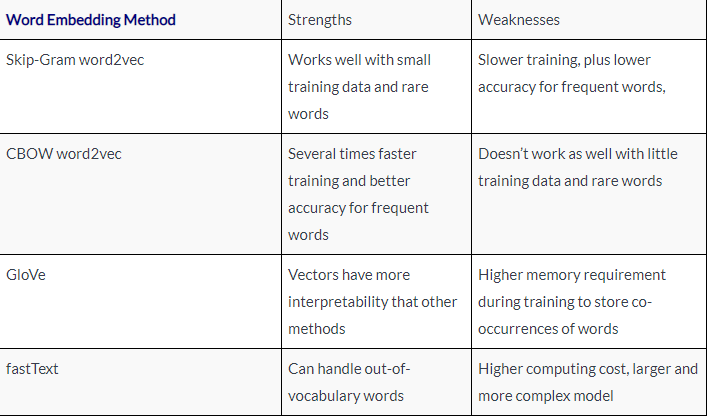
As was outlined in the first chapter of this book, this important sub-area of NLP research has a rich history originating with the term-vector model of information retrieval in the 1960s. This culminated with pretrained shallow neural-network-based techniques such as fastText, GloVe and word2vec — which came in several variants in mid 2010s including Continuous Bag of Words (CBOW) and Skip-Gram. Both CBOW and Skip-Gram are extracted from shallow neural networks that were trained for various goals. Skip-Gram attempts to predict words neighboring any target word in a sliding window, while CBOW attempts to predict the target word given the neighbors. GloVe — which stands for “Global Vectors” — attempts to extend word2vec by incorporating global information into the embeddings. It optimizes the embeddings such that the cosine product between words reflects the number of times they co-occur, with the goal of making the resulting vectors more interpretable. The technique fastText attempts to enhance word2vec by repeating the Skip-Gram methods on character n-grams (versus word n-grams) thereby being able to handle previously unseen words. Each of these variants of pretrained embeddings have their strengths and weaknesses, and these are summarized in Table 1.
To reiterate, fastText is known for its ability to handle out-of-vocabulary words, which comes from it having been designed to embed sub-word character n-grams or sub-words (versus entire words as is the case with word2vec). This enables it to build embeddings up for previously unseen words by aggregating composing character n-gram embeddings. That comes at the expense of a larger pretrained embedding, and higher computing resource requirement and cost. For these reasons, we elect to use the fastText framework as the representative pretrained word embedding computing method in this section, albeit with the word2vec input format. This allows us to keep the computing cost lower, making the exercise easier for the reader, while also showcasing how out-of-vocabulary issues would be handled and providing a solid experience platform from which the reader can venture into sub-word embeddings.
Let’s begin the computing experiment! The first thing we need to do is obtain the appropriate pretrained word embedding file. Since we will be using the fastText framework, we could obtain these pretrained files from the authors’ official website[2] which hosts appropriate embedding files in a number of formats. It is important to note that these files are extremely large, since they attempt to capture vectorization information about all possible words within a language. For instance, the .vec format embedding for the English language, which was trained on Wikipedia 2017, and provides vectorization information without handling sub-words and out-of-vocabulary words, is about 6 Gigabytes in size. The corresponding .bin format embedding, which contains the famous fastText sub-word information, and can handle out-of-vocabulary words is about 25% larger at approximately 7.5 Gigabytes. We also note that Wikipedia embeddings are provided in up to 294 languages, even including traditionally unaddressed African languages such as Twi, Ewe and Hausa. It has however been shown that for many of the included low-resource languages, the quality of these embedding is not very good[3].
Due to the size of these embeddings, it is a lot easier to execute this example using the recommended cloud-based notebooks we have hosted on Kaggle (versus running them locally) because the embedding files have already been openly hosted in the cloud environment by other users[4]. As such, they can be simply attached to a running notebook without having to obtain and run the files locally.
Once the embedding is available, it can be loaded using the following code snippet, making sure to time the loading function call:
import time
from gensim.models import FastText, KeyedVectorsstart=time.time()
FastText_embedding = KeyedVectors.load_word2vec_format("../input/jigsaw/wiki.en.vec") # A
end = time.time()
print("Loading the embedding took %d seconds"%(end-start))
# A Load pre-trained fastText embedding in “word2vec” format (without “sub-word” information)
Loading the embedding takes more than 10 minutes the first time on the Kaggle environment we used for execution. In practice, in such a situation, it is not uncommon to load the embedding once into memory and then serve access to it using an approach such as flask for as long as it is needed. This can also naturally be achieved using the Jupyter notebook that comes along with this chapter of the book.
Having obtained and loaded the pre-trained embedding, let’s look back at the IMDB movie review classification example, which we will be analyzing in this section. In particular, we pick up right after Listing 2.10 of the book in the preprocessing stage of the pipeline, which generates a Numpy array raw_data containing word-level tokenized representations of movie reviews, with stopwords and punctuations removed. For the reader’s convenience, we show Listing 2.10 again next.
Listing 2.10. (From chapter 2 of the book) Function and calling script for loading IMDB data into Numpy array.
def load_data(path):
data, sentiments = [], []
for folder, sentiment in (('neg', 0), ('pos', 1)):
folder = os.path.join(path, folder)
for name in os.listdir(folder): # A
with open(os.path.join(folder, name), 'r') as reader:
text = reader.read()
text = tokenize(text) # B
text = stop_word_removal(text)
text = remove_reg_expressions(text)
data.append(text)
sentiments.append(sentiment) # C
data_np = np.array(data) # D
data, sentiments = unison_shuffle_data(data_np, sentiments)return data, sentiments
train_path = os.path.join('aclImdb', 'train') # E
raw_data, raw_header = load_data(train_path)
# A Go through every file in current folder
# B Apply tokenization, stopword analysis routines
# C Track corresponding sentiment labels
# D Convert to Numpy array
# E Call function above on data
Imagine a simple bag-of-words representation for the output Numpy array — which counts occurrence frequencies of possible word tokens in each review — and use the resulting vectors as numerical features for further machine learning tasks. Here, instead of the bag-of-words representation, we extract corresponding vectors from the pre-trained embedding instead.
Since our embedding of choice does not handle out-of-vocabulary words out-of-the-box, the next thing we do is to develop a methodology for addressing this situation. The simplest thing to do, quite naturally, is to simply skip any such words. Since the fastText framework errors out when such a word is encountered, we will use a try and except block to catch these errors without interrupting execution. Assume that you are given a pretrained input embedding that serves as a dictionary, with words as keys and corresponding vectors as values, and an input list of words in a review. Listing 2 shows a function that produces a 2-dimensional Numpy array with rows representing embedding vectors for each word in the review.
Listing 2. Function that produces an output 2D Numpy array with rows corresponding to embeddings vectors for words in a movie review.
def handle_out_of_vocab(embedding,in_txt):
out = None
for word in in_txt: # A
try:
tmp = embedding[word] # B
tmp = tmp.reshape(1,len(tmp))if out is None: # C
out = tmp
else:
out = np.concatenate((out,tmp),axis=0) # D
except: # E
pass
return out
# A Loop through every word
# B Extract corresponding embedding vector and enforce “row shape”
# C Handle edge case of the first vector and an empty out array
# D Concatenate row embedding vector to output Numpy array
# E Skip execution on current word and continue execution from the next word when out-of-vocabulary errors occur
The function in Listing 2 can now be used to analyze the entire dataset as captured by the variable raw_data. Before doing this we must decide how to combine or aggregate the embedding vectors for individual words in a review into a single vector representing the entire review. The heuristic of averaging the words works as a strong baseline. Because the embeddings were trained in a way that ensures that similar words are closer to each other in the resulting vector space, it makes intuitive sense that their average represents the average meaning of the collection. The averaging baseline for summarization/aggregation is often recommended as a first step in embedding bigger sections of text from word embeddings. This is also the approach we use in this section as demonstrated by the code in Listing 3. Effectively, this code calls the function from Listing 2 repeatedly on every review in the corpus, averages each output and concatenates the resulting vectors into a single 2D Numpy array with rows corresponding to aggregated-by-averaging embedding vectors for each review.
Listing 3. Function and calling script for loading IMDB data into Numpy array.
def assemble_embedding_vectors(data):
out = None
for item in data: # A
tmp = handle_out_of_vocab(FastText_embedding,item) # B
if tmp is not None:
dim = tmp.shape[1]
if out is not None:
vec = np.mean(tmp,axis=0) # C
vec = vec.reshape((1,dim))
out = np.concatenate((out,vec),axis=0) # D
else:
out = np.mean(tmp,axis=0).reshape((1,dim))
else:
pass # Ereturn out
# A Loop through every IMDB review
# B Extract embedding vectors for every word in review, making sure to handle out-of-vocab words
# C Average word vectors in each review
# D Concatenate average row vector to output Numpy array
# E Every-word-out-of- vocab edge case handling
We can now assemble embedding vectors for the whole dataset using the function call:
EmbeddingVectors = assemble_embedding_vectors(data_train)
These can now be used as feature vectors for the logistic regression and random forest codes which can be found in Chapter 2 of the book (also see our companion github repo[5] for Kaggle notebook links which you can access for free). Using these codes to train and evaluate these models, we found the corresponding accuracy scores to be 77% and 66% respectively when the hyperparameters maxtokens and maxtokenlen are set to 200 and 100 respectively, and the value of Nsamp, i.e., the number of samples from each class, being equal to 1000. These are only slightly lower than the corresponding values obtained from the bag-of-words baseline that was initially developed in Chapter 2 of the book (corresponding to accuracy scores of 79% and 67% respectively). We hypothesize that this slight deprecation is likely due to the aggregation of individual word vectors by the naive averaging approach that was described. In the next section, we attempt to perform more intelligent aggregation using embedding methods that were designed to embed at a higher text level.
Semi-supervised Learning with Higher-Level Representations
Several techniques were inspired by word2vec to try to embed larger section of text into vector spaces in such a way that sentences with similar meanings would be closer to each other in the induced vector space. This enables arithmetic to be performed on sentences to make inference with regards to analogies, combined meanings, etc. One prominent approach is paragraph vectors or doc2vec, which exploits the concatenation (vs. averaging) of words from pretrained word embeddings in summarizing them. Another is sent2vec, which extends the classic Continuous Bag-of-Words (CBOW) of word2vec — where a shallow network is trained to predict a word in a sliding window from its context — to sentences by optimizing word and word n-gram embeddings for an accurate averaged representation. In this section we use a pretrained sent2vec model as an illustrative representative method and apply it to the IMDB movie classification example.
A few open source implementations of the sent2vec can be found online. We elect to employ a heavily-used implementation that builds on fastText[6]. To install that implementation directly from its hosted URL, one can execute the following command:
pip install git+https://github.com/epfml/sent2vec
Quite naturally, just as in the case of the pretrained word embeddings, the next step is to obtain the pretrained sent2vec sentence embedding to be loaded by the particular implementation/framework installed. These are hosted by the authors of the framework on their GitHub page, and on Kaggle by other users[7]. We choose the smallest 600-dimensional embedding wiki_unigrams.bin, approximately 5 Gigabytes in size, which captures just the unigram information on Wikipedia. This choice is driven by simplicity considerations. We note that significantly larger models are available pretrained on book corpuses and Twitter, and also including bigram information.
Having obtained the pre-trained embedding, we load it using the following code snippet, making sure to time the loading process as before:
import time
import sent2vecmodel = sent2vec.Sent2vecModel()
start=time.time()
model.load_model('../input/sent2vec/wiki_unigrams.bin') # A
end = time.time()
print("Loading the sent2vec embedding took %d seconds"%(end-start))
# A Load sent2vec embedding
We found the load time during the first execution to be less than 10 seconds, a notable improvement over the fastText word embedding loading time of over 10 minutes that is worth mentioning before proceeding. This is attributed to the significantly more efficient implementation of the current package, versus the gensim implementation that was used in the previous section. It is not uncommon to try a few different packages to find the most efficient one for your application in practice.
Next, we define a function to generate vectors for a collection of reviews. It is essentially a simpler form of the function presented in Listing 4 for pretrained word embeddings — it is simpler as we do not need to worry about out-of-vocabulary words. This function is shown in Listing 4.
Listing 4. Function and calling script for loading IMDB data into Numpy array.
def assemble_embedding_vectors(data):
out = None
for item in data: # A
vec = model.embed_sentence(" ".join(item)) # B
if vec is not None: # C
if out is not None:
out = np.concatenate((out,vec),axis=0)
else:
out = vec
else:
passreturn out
# A Loop through every IMDB review
# B Extract embedding vectors for every review
# C Edge case handling
We can now use this function to extract sent2vec embedding vectors for each review as follows:
EmbeddingVectors = assemble_embedding_vectors(data_train)
We can now split this into training and test data sets, train logistic regression and random forest classifiers on top of the embedding vectors, etc., as before. This yields accuracy scores of 82% and 68% for the logistic regression and random forest classifiers respectively (at the same hyperparameter values as in the previous section). This value for the logistic regression classifier combined with sent2vec is an improvement on the corresponding values of 79% and 67% respectively for the bag-of-words baseline, as well as being an improvement over the averaged word embedding approach from the previous section.
That’s all for this article. If you want to learn more about the book, you can check it out on our browser-based liveBook reader here.