In recent years, the area of self-supervised representation learning is very popular and has shown to be very effective in improving the performance of many tasks.
In this blog post, let’s understand the latest research paper Exploring Simple Siamese Representation Learning by Xinlei Chen and Kaiming He from Facebook AI Research.
If you are an advanced reader familiar with self-supervised learning and representation learning, you can directly skip to the section Present Solutions.
As the name is very evident, it is a family of learning algorithms that can learn the task in a self-supervised manner, i.e., there is no need for manually labeled data.
In representation learning, we develop representation vectors for an image (or text or audio). Let us say that there is an image of a dog of size 256×256 with all 3 colors. The image has pixel data in the form of a 256x256x3 tensor. In representation learning, we try to develop a vector of size 1×1024 (or any suitable dimension) that captures higher-level abstract information about the image instead of just raw pixels.
This is done by taking similar images (or texts or sounds) and forced to have similar representation vectors.
The problem with simple self-supervised representation learning is after a few epochs, the model learns an identity mapping — for all the images, it outputs the same vector. This happens because we want representation vectors to be similar. An identity mapping gives the same representation, so the model’s cosine similarity loss becomes Zero.
Despite a zero loss during the training process, the representations learned are useless as all images get the same representation.
The problem of collapsing to identity mapping in self-supervised representation learning is solved in the following way:
- Negative samples in the paper SimCLR, and MoCo. The idea is to use negative samples, and our loss function measures not just similarity of representation for similar images but also dissimilarity between different images.
Note 1: Supervised Contrastive Learning also uses negative samples, but it is not self-supervised, so it is not mentioned.
Note 2: MoCo also uses the moving average method but not exclusively.
- Online clustering in the paper SwAV. The idea is to cluster the images and use the clusters as positive and negative samples.
- Moving average in the paper BYOL. The idea is to use a network with a moving average to take the representation of similar samples. This approach does not need any negative samples.
A single sentence summary of this entire paper is
BYOL without momentum encoder. SimCLR without negative samples. SWaV without online clustering
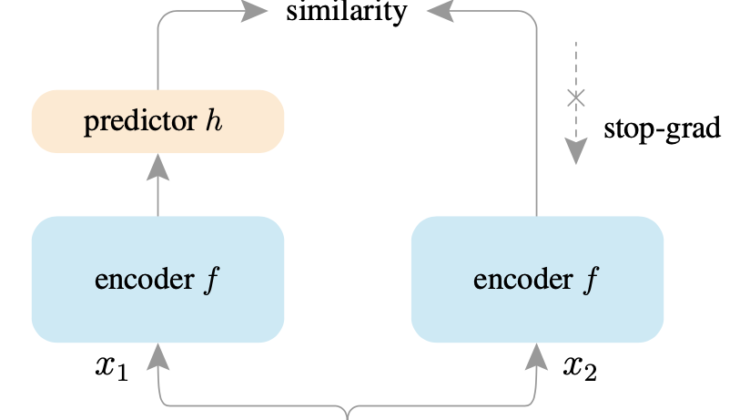
The authors of this paper discovered that even after removing all the additional structures (like negative samples, clustering, and moving averages) added to prevent the model from collapsing to identity mapping. The model can learn good representations.
Only the stop-grad operation is sufficient to get comparative results on downstream tasks. In the stop-grad method, we make all the gradients that flow through that branch Zero, so only the Encoder-Predictor branch gets updated at the training step.
This method is surprisingly simple and shows that Siamese Networks have great capabilities in developing representations.
Note 3: The BYOL paper in arXiv update v3 does the same procedure in the pre-training phase for 300 epochs with a 10x learning rate. This work is done concurrently and should be recognized.
It is evident that the simplicity of SimSiam is more successful than all the remaining methods for the first 100 epochs. It is also evident that more advanced methods like BYOL have an advantage when trained for a higher number of epochs.
A huge advantage of the SimSiam approach is the smaller batch size, so this method requires very less compute resources.
References
- SimSiam —
Exploring Simple Siamese Representation Learning - SimCLR —
A Simple Framework for Contrastive Learning of Visual Representations - SimCLRv2 —
Big Self-Supervised Models are Strong Semi-Supervised Learners - BYOL —
Bootstrap Your Own Latent: A New Approach to Self-Supervised Learning
For more interesting paper explained blog posts, please follow and share.