First of all, what is concurrency?
Concurrency is when there are multiple threads running simultaneously in one process on a CPU core (each thread is an independent sequence of execution). Each of these threads shares the same memory space as the other threads.
FYI: You may also have heard of the term parallelism. This refers to having multiple independent processes running on different cores of the CPU. In Python, you can utilize multi-processing to do so, but depending on the context of your program, it may not be encouraged. I will not be discussing multi-processing in this article. We will be focusing on concurrency.
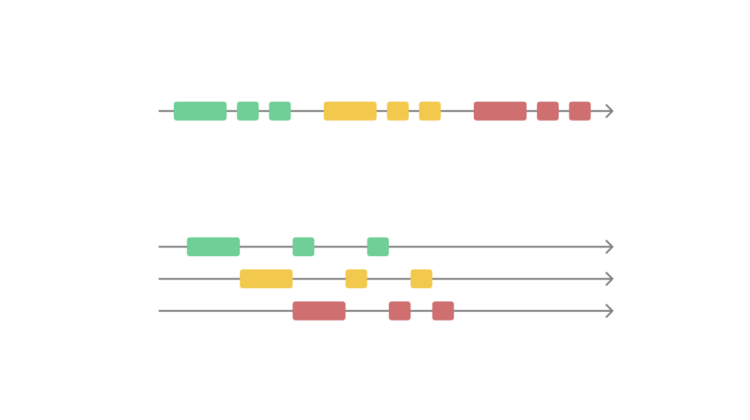
I created the illustration below to help visualize the difference between concurrency and parallelism (this is a simplified view, of course):
Global Interpreter Lock (GIL)
When we talk about multi-threading and concurrency in Python, the Global Interpreter Lock (or GIL) has to be mentioned.
In Python (CPython implementation), there is something called GIL that ensures that only one thread can be running at one time (as CPython’s memory management is not thread-safe). With GIL, we can be assured that we will not face any race conditions for our threads.
Although only one thread can be running at one time, it is still much faster to utilize concurrency because web scraping is a very IO-bound task as mentioned, where a lot of time is spent waiting for the network. Multi-threading can boost the speed of web scraping tremendously.
For illustration’s sake, this is how it looks!
Let’s show some examples!
For the rest of this article, we will scrape IMDb’s 100 most popular movies and save them into a .csv file.
I may write a separate article on how to web scrape in detail, but I’ll keep that out of the way for now, as it’s not the aim of the article.
To web scrape, I’ll be using Python Requests and Beautiful Soup (for easy HTML parsing) to get the data needed. You will not need any extra out-of-the-box tools.
As mentioned, I have prepared a Google Colab notebook (click “Open in Colab to run the notebook), but I recommend only visiting it after reading this article, as most explanations are contained here. Regardless, I will cover all parts of the code here as well.
Feel free to skip the next section if you are already familiar with web scraping.