There are so many machine learning algorithms out there, how do you choose the best one for your problem? This question is going to have a different response based on the application and the data. Is it classification, regression, supervised, unsupervised, natural language processing, time series? There are so many avenues to take but in this article I am going to focus on on algorithm that I particularly find very interesting, XGBoost.
XGBoost stands for extreme gradient boosting and is an open source library that provides an efficient and effective implementation of gradient boosting. To understand what XGBoost is we must first understand gradient boosting.
Wisdom of the Crowd
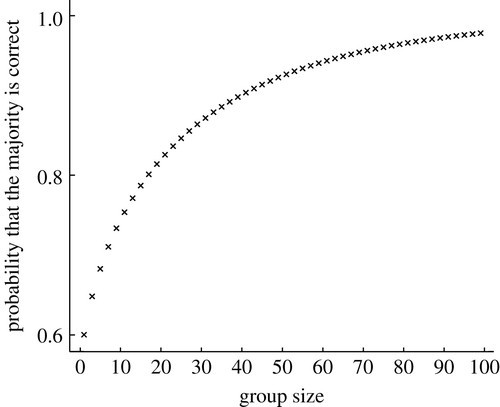
Boosting is based off the idea of wisdom of the crowd, where the opinions of a large enough group can be more accurate or stronger than that of an expert. For example, if you are at an art auction and you are trying to prove if a painting is counterfeit, would you rather have 100 art lovers with a 60% chance of predicting correctly whether that art is real or one expert with an 80% chance. This is an example of Condorcet’s Theorem where we can see in this graph, the wisdom of the crowds prevails.
As your group size increases even if the chance is barely above random (50%) with enough people the decision of the group will most likely be correct. This is why we have a group of people in a jury rather than just one person.
Boosting
Boosting is based off the idea of wisdom of the crowds except the crowd is a group of less powerful machine learning models rather than people. The less powerful models are called “weak learners” and they are made in a way that they each focus on a different problem that the model encounters. The process starts with building a model from the training data, then building a second model on those examples that the first model missed. This process then continues building more and more models trying to fill in the gaps so that eventually if we were to take a vote a majority of the weak learners will predict correctly. This process could go on forever so some stopping criteria is needed like max number of models or minimum prediction accuracy.
Gradient Boosting
Gradient boosting is an application of boosting but also takes inspiration from gradient descent which is used for machine learning algorithms like linear regression. The basic idea of gradient descent is by taking the derivative of the loss function you are able to get the gradient or slope of the loss function at a certain point. The value of that derivative (either positive or negative) can tell you what direction you need to go in order to minimize the loss function. The more the slope of that loss function is the closer you are to reaching a local minimum.
The way that this is applied to boosting is that the loss function used to assess the trees needs to be differentiable and therefore you are able to calculate the gradient. The model will then change parameters in order to further decrease the loss function.
XGBoost is just a tuned version of gradient boosting so it functionally works in the same way. The difference and the reason people use XGBoost over vanilla gradient boosting is for its execution speed and model performance. There are many optimizations made to gradient boosting but the main changes are as follows:
Gradient boosting only calculates first-order gradients meaning it will take the derivative of the loss function and go no further. XGBoost will compute second-order of the loss function in order to gain more information on how the model should change in order to obtain better results. The information gained is specifically on how the loss function is behaving and how parameter changes will affect the loss function.
The other major change is the advanced regularization XGBoost used in order to generalize better. Regularization helps the model not to overfit by not letting the model learn the noise within the data. If the model can only learn the most important aspects of data it will not be tripped up with the finer changes in data but be able to see the “bigger picture”
XGBoost is an amazing algorithm and can be used for both regression and classification. Here is a snippet of code I used to classify the outcome of major league baseball games using XGBoost.
There are many different machine learning algorithms and many different variants of each of those so how do you choose the best one? Now that machine learning is becoming such a large industry there are new findings all the time on what model can perform best on what kind of problem. The way to find the best one is to keep up to date on what new algorithm or version of an algorithm has been developed and try them out. There is a certain level of planning you can do to choose an algorithm that fits your data well but you can never know until you try.