This article will explore the application of distributed messaging within the Machine Learning space and analyze Apache Pulsar as a more efficient solution to Apache Kafka.
With the ever increasing velocity of big data and the perpetual refinement of machine learning (ML) solutions, more companies are opting to integrate ML to inform their business decisions. However, as per a recent Alegion research survey, roughly 96% of machine learning initiatives fail. Why is that? The ML space itself is deeply complex, but this high level of complexity is not the reason that most initiatives fail. Instead, the issue arises from handling such large volumes of data. For the past decade, most companies have used a distributed messaging system, specifically Apache Kafka, to solve issues at such scales. But, with never before seen scaling and more complex systems, Kafka design begins to undermine its own performance.
Distributed messaging systems act as an architecture enabling communication between programmatic entities. Traditional distributed messaging systems have three main components: Publish / Subscribe architecture, Queuing, and Event Streaming. Distributed messaging systems handle scaling by decoupling monolithic applications into efficiently partitioned sets. Classically, a distributed messaging system acts as a pipeline to consume and process data and while this may work for a well defined endpoint, ML applications are much less defined. The same data may be reused within a ML application and the outputs of one epoch may be used as inputs in the next epoch. Essentially, there exists a feedback loop within ML applications and operationalizing ML in a classical application becomes deeply convoluted.
While Kafka has been the leader in distributive messaging solutions, it’s initial design was not intended to handle the complexity of architecture that ML requires. One of the biggest challenges that Kafka faces in ML is scalability. Kafka bins both compute and storage together and in an environment where compute and storage have very high usage rates, this space can fill quickly. Additionally, Kafka is not an all encompassing solution to ML applications. Kafka does not include a queuing functionality. An additional framework, such as RabbitMQ, must be imported for queuing. Overall, Kafka was not designed to handle ML applications and it typically must be retrofitted to handle such operations.
Apache’s up and coming Pulsar framework is much more equipped to handle ML applications. Pulsar acts as the central nervous system within an ML application. By unifying event streaming, queuing and publish / subscribe architectures, Pulsar positions itself as the cornerstone of ML applications. Additionally, Pulsar separates compute and storage. By doing so, both compute and storage can scale independently of each other and this does well to add robustness at higher levels of scalability, as well as alleviate operational pain in development. Additionally, Pulsar outperforms Kafka with the following:
Below is a spreadsheet courtesy of Splunk’s blog on a theoretical dataset. If you would like to learn more about Pulsar’s data storage options, please visit their blog.
Ultimately for any ML application, Pulsar is the clear winner. As the ML space becomes more and more complex, Kafka will eventually become obsolete. Companies looking to implement ML on a large scale will have to make the switch to a new distributed messaging system.
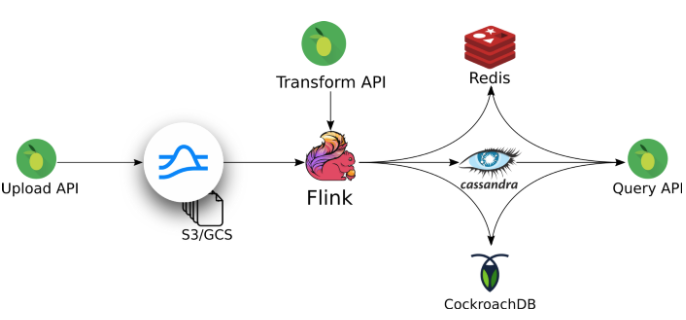
StreamSQL, an event sourcing based ML operations platform, recently made the switch from Kafka to Pulsar. Essentially, StreamSQL is a query language that extends the reach of SQL to handle and process real-time data streams. Below are StreamSQL’s architectures for their old Kafka based solution and their new Pulsar based solution.
KAFKA BASED SOLUTION
(Image courtesy of SteamSQL)
StreamSQL’s application required that events persist indefinitely and since Kafka did not implement a tiered storage, StreamSQL had to keep feeding this framework with more storage and with larger and larger topics, the performance suffered greatly. Additionally, SteamSQL had to implement Apache Spark to support Kafka’s Processing. With so many coordinating systems, the architecture as a whole is more prone to errors and actual application becomes more expensive.
PULSAR BASED SOLUTION
(Image courtesy of SteamSQL)
Conversely, Pulsar does not require Spark to support processing and with Pulsar’s integrated tiered storage, inactive event logs can be offloaded to S3. With this functionality, StreamSQL was able to infinitely persist events in a cheap and effective way. StreamSQL no longer has to keep feeding their system storage and implementation is much more linear.
If you would like to learn more about StreamSQL’s switch to Pulsar please visit their blog.
For any company interested in achieving ML or artificial intelligence, Pandio can help. Pandio utilizes a Pulsar framework with an integrated neural network. The neural network controls all of Pulsar and dynamically adapts to the requirements of the project’s applications. With this feature, not only will you get all the functionality of Pulsar, but you will get a more optimized version of Pulsar. This means cheaper operational expenses with higher efficiency.
Pandio can help your company make the switch over to Pulsar. If you would like to know more about Pandio, please explore our website.