There are many different types of Machine Learning systems base on each criterion.
This criterion has 4 main types: supervised, unsupervised, semi-supervised, and reinforcement learning.
- Supervised Learning
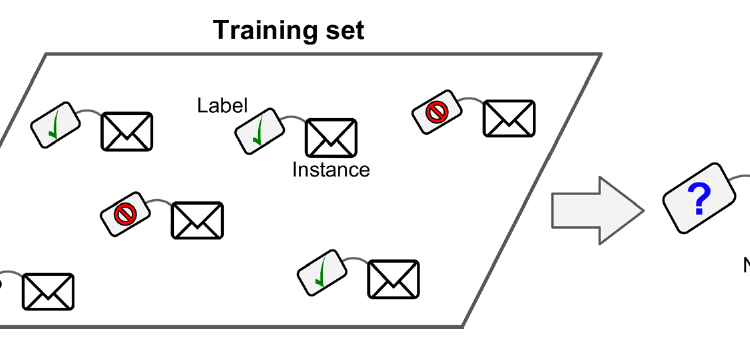
As the name indicates, supervised learning has the presence of a supervisor as a teacher. We train our program using data that is “well labeled” — data is tagged with the correct answer.
Classification is a typical supervised learning task. One example is the spam filter. In the training set, every email was tagged with its class (spam or not). After learning from the data set, the Machine Learning program will answer the question where or not the new coming email is a spam email.
Regression is another typical supervised learning task. In this task, the program has to predict a target numeric value, such as the price of a car, given a set of features (brand, mileage, age, etc.) called predictors. In the training set, every car will include both its predictors and their labels (in this case, the prices)
Some important supervised learning algorithm
2. Unsupervised Learning
In the opposite of Supervised Learning, there is no teacher in Unsupervised Learning. In another word, the training data is unlabeled.
One of the most important Unsupervised Learning is Clustering. The goal of clustering is to determine the internal grouping in a set of unlabeled data.
For example, You have a lot of data about your website’s visitors. The clustering algorithm will help to detect groups of similar visitors. It may found that 30% of your visitors are males and want to buy watches, while 15% of your visitors are females and want to buy phones. So, base on each clustering, you will decide the right marketing campaign for each group.
Some important Unsupervised Learning algorithm:
- Clustering: K-Means, DBSCAN, Hierarchical Cluster Analysis
- Anomaly detection and novelty detection: One-class, SVM, Isolation Forest
- Visualization and dimensionality reduction: Principal Component Analytics, Kernel PCA, Locally Linear Embedding, t-Distributed Stochastic Neighbor Embedding
- Association rule learning: Apriori, Eclat
3. Semisupervised Learning
This is a mix of Supervised Learning and Unsupervised Learning. Normally, labeling data is costly, so the training data may come with a partially labeled set.
Most semisupervised algorithms are combinations of supervised and unsupervised algorithms.
4. Reinforcement Learning
It is about taking suitable action to maximize reward (or minimize penalties) in a particular situation. In this type of Machine Learning, an agent (the learning system) can observe the environment, select and perform actions and get rewards in return. In the end, it will try to find the best strategy (policy) to get the most reward over time.
There are some implementations of Reinforcement Learning algorithms in the real world; for example, DeepMind’s AlphaGo, learns how to walk by robots.
- Batch Learning (Offline Learning)
If training is taking a lot of time and computer resources, so it must typically do offline. The system first trains with data and then launch in production lately without learning. This is also called offline learning.
If the system wants to learn the new data set, we need to gather all old and new data and make the system train again with the new version of data. After training, we have the new version of the system, and we can replace the old one with this new one.
We can achieve the whole above steps automatically, so we can scheduler the training frequently. However, if we need the system to adapt rapidly change (predict stock prices hourly), then we need more reactive solutions.
2. Online Learning
When the training is cheap and fast by learning from mini-batches, the system can learn on the fly as data arrives.
Online Learning is great for the system that needs to answer questions quickly, for example, stock prices.
The big problem with Online Learning is bad data. If the system learns from bad data on the fly, the new version can perform the bad result, and users can notice that.
- Instance-based Learning
The system learns examples by heart, then generalizes to a new case by using similarity measures to compare them to learned examples. It also knows as Memory-based Learning or Lazy Learning.
If we apply instance-based Learning into the email spam filter program, then instead of just flagging emails that are identical to know spam emails, we can flag emails that are very similar to know spam emails. (maybe we can count common words between two emails as the similarity)
2. Model-based learning
In this way, we generalize a set of examples to build a model and then use that model to make predictions.
Let take a look at the examples about the data set of each country with GDP per capita and life satisfaction. And answer the question, does money make people happier?
By taking a look at the figure, we can notice a trend here. So we can start with the very simple linear model for the above data.
life_satisfaction = X0 + X1 x GDP_per_capita
We try to find X0 and X1. And then we can predict the life_statisfaction for the new coming country with its GDP_per_capita.