A hybrid approach combining symbolic processing with distributed representations
Extracting all the different ways a particular term can be referred to (synonym harvesting) is key for applications in biomedical domain where drugs, genes etc. have many synonyms. While there are human curated knowledge bases for synonyms in the biomedical domain, they are generally incomplete, continually trying to play catchup as new drugs are discovered and referred to in different ways (active ingredient, standardized drug codes, brand names, etc) . This is in part because the synonym mention for a term usually shows up first in sentences — manual curation of synonyms would require going through large amounts of literature. Also the average number of synonyms for some entity types like drugs or genes are quite high making the curation process challenging. For instance, there are drugs that can be referred to by over 15 different names.Even popular search engines have not completely addressed the synonym problem for common terms like drugs, an example of which is shown below
Automated harvesting of synonyms is essentially a relation extraction problem where the synonym terms and the phrases relating them are typically in close proximity — that is within a few word hops of each other. This simplicity in sentence structure facilitates extracting them with different degrees of success (measured in precision and recall) ranging from traditional rule based approaches (regular expressions/ sentence templates) to modern supervised machine learning methods and recently unsupervised methods for certain kinds of relation extractions(examined in related work below) . The choice of approach is a trade-off between at least three factors (1) performance — in particular precision (2) ease of implementation and maintenance (3) need for labeled data if the approach requires a supervised model.
This article describes an approach to harvest all synonyms for a term (term here refers to both phrases and single words) purely from unstructured text without any requirement for labeled data, extraneous structured data or knowledge graphs. The approach has high precision (except when input sentence/fragment is incomplete- which can be addressed) and is easier to build and maintain than regular expression/template driven approaches. Supervised models are arguably easier to maintain than this approach if one has labeled data for training. This method could be used to create such a supervised model and also be used in concert with it as an ensemble to improve performance.
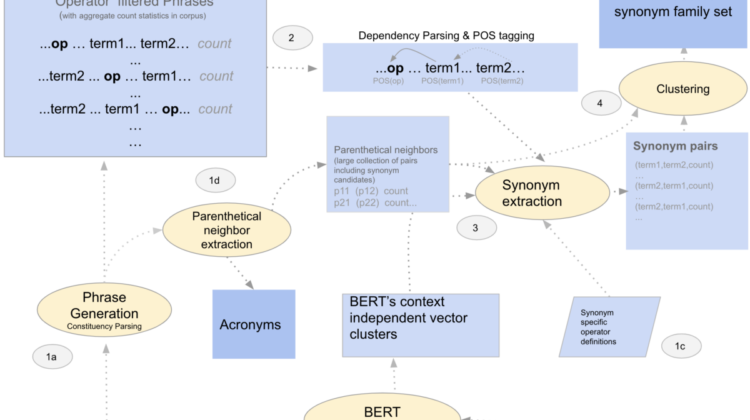
This approach leverages off the fact that there exists sentences in a sufficiently large corpus where synonym terms are within a few “syntactic dependency hops” from the term linking those two (or more) synonym terms in the relationship. In contrast to templates driven methods to capture relations, this approach treats the linking terms as operators with specific properties (captured in a relation specific configuration). Operators naturally capture prefix, infix and postfix operations (obtained by parsing a sentence with a dependency parser) without the need for separate sentence/fragment templates capturing all operator configurations as well as word sequence combinations. For this reason it generalizes better than template driven approaches or regular expressions.
How does this work? Sentence fragments extracted using a constituency parser (or with POS tagger/chunker combo) are converted into a tagged graph using a dependency parser. The terms in the sentence fragments are also mapped to BERT’s context independent vector clusters, yielding operators, operator attributes, etc. The dependency parser output along with the mapped cluster attributes of terms are used to perform operator specific validations (operator properties such as commutativity, range, specificity etc. defined upfront as a one-time configuration) and to extract term pairs that are synonyms.
The advantages of this approach are
- it sets the baseline performance for more sophisticated models, particularly supervised models
- it can complement sophisticated models in real time applications.
- it can be used as a data augmentation scheme to generate labeled data for supervised models
- this can be used for relation extraction broadly, given some constraints/assumptions. It could also find use in certain applications where the nature of relationship between terms determines how a sentence can be classified.
The limitations of this approach are
- few sentence structures are beyond the scope of this approach, despite satisfying the proximity constraint. In practice, this limitation can potentially be overcome if the input corpus is large enough — there would be sentences capturing synonym relation between term pairs whose simpler structures lend themselves to extraction with this approach.
- its efficacy is largely limited to finding relations where the relation and the terms linked by the relation are within a few “syntactic dependency hops” of each other — a constraint synonym terms largely satisfy, but is not true in general for other relation types that could potentially span large distances even across sentences. In practice however, for many kinds of relations there exists sentences that fall within the efficient operating region of this approach.
- it can pick up false positives if the input sentence or fragments are incomplete — this could be mitigated to some degree (examined below)
While the details below focus on harvesting synonyms from unstructured text, most of the steps, with the exception of a few, are applicable to other relation extraction problems (with the constraints mentioned earlier) and are not specific to synonym extraction.
1a. Phrase generation
Phrase generation outputs sentence fragments or phrases with word spans roughly equalling the output of a constituency parser traversed down from two level up the constituency parse tree. This could be done by constituency parser or even a simple POS tagger, chunker combo for performing this at scale (constituency parser could be slow for phrase generation at scale).
The key advantages of offline phrase generation are
- Phrase generation serves as a full pass on a large input corpus to aggregate phrases. This enables us to determine aggregate signals between two entities. Attempting to do this in realtime without aggregation requires a large number of sentences making such an approach infeasible if not computationally prohibitive for a real-time application (exception is real time extraction from few new documents as they appear — this can be done in real time). Aggregate counts of phrases is a useful signal to eliminate or penalize sentences that are incomplete (they could lead to incomplete phrase fragments) and could lead to precision loss in harvesting synonyms — given there occurrence counts would be typically low.
- Phrases are shorter in length on average than full sentences which is favorable for this form of extraction using a dependency parser.
- In addition to extracting sentence fragments, phrase generation also yields phrases of the form term1 (term2). These are instances where humans have manually annotated term1 with term2 for a variety of reasons. A predominant (but not exclusive) reason is for acronyms and synonyms. These phrases referred to below as parenthetical neighbors can be utilized for both extraction of large scale extraction of acronyms as well as synonym candidates from text. Synonym candidates come in handy to validate/corroborate the extraction of synonyms from sentences.
1b. Pre-training BERT on domain specific corpus using a custom vocabulary created from that corpus
This step is critical for maximizing performance particularly in domain specific corpus. Fine tuning an existing model on a domain specific corpus may not be enough if the domain specific vocabulary is distinct from the standard vocabulary of a pre-trained BERT model.
After pre-training, the context independent vectors are clustered where the threshold for a cluster is done on an individual cluster basis ensuring distinct distribution tails. Each of these clusters will serve as an operator, operand, operator scaler or just a glue word for synonym harvesting. This is a one-time step that is more equivalent to feature engineering than to creating labeled data.
1c. Choice of operators and operator scalers
The task of choosing operators for a relation is as mentioned above a one-time feature engineering step, aided by BERT’s context independent vectors.
For the task of synonym extraction, the following clusters in BERT’s context independent vectors are examples of operator candidates (from a total of ~20)
A key advantage of this approach compared to template based approaches is that by just identifying a few operators (~20 for synonym task) one can leverage off a dependency parser/POS tagger combo to match and filter a large combination of phrases/fragments that are synonym candidates as shown below.
Relation Extraction (2–4 in figure 1 above)
The operators chosen in stage 1c (Figure 1) is used to filter phrase candidates from phrase generation output that will be used for synonym harvesting. The phrase generation output is also used to extract acronyms from parenthetical neighbor phrases of the form term1 (term2), the remains of which is used in the synonym harvesting step of stage 3.
The dependency graph of each operator filtered fragment is used to harvest synonym pairs. The parser sets the scope of these operators. Noun phrases that will within this scope are the synonym candidates. Invalid fragments that do not obey operator rules are dropped. Valid fragments are scored based on the operator, and the scalers that fall within the scope. Fragments that meet a threshold score are chosen and the synonym pairs harvested from them. The synonym pairs could be optionally validated further using NER (e.g. unsupervised NER)
The chosen synonym pairs are first aggregated. Two kinds of operator types are used to harvest synonym pairs — one is synonyms of the form “a is also know as b” and and sentences that capture synonym families “a such as b”. Once synonym pairs are aggregated, clustering creates an equivalence class of synonym sets following the simple rules of symmetry and transitivity — a R b → b R a and a R b, b R c → a R c. Synonym family terms are identified by operators that are not symmetric, in contrast (“such” in “statins such as atorvastatin”, is not symmetric)
Finding the pivot term of a synonym set is done by two signals present in the data. The pivot term of a set is the node whose subtree of all related terms is the largest. Additionally parenthetical neighbors (from 1d in figure 1), help could offer an additional cue in finding the pivot term of a set — parenthetical neighbors involving the pivot term of a set typically has the largest number of parenthetical pairs where the pivot term is the parenthetical term and not vice versa. That is if “a” is the pivot term then it is more likely to find a high count of x (a) as opposed to a (x) — simply because the well known name of a term needs to be rarely qualified whereas a less well know version requires qualification.
Parenthetical neighbors assist in synonym harvesting in multiple ways
- additional evidence to synonym harvested from sentences. A term that is mentioned as a synonym to another in sentence form often is also mentioned as parenthetical neighbor the term, typically with occurrence counts exceeding the sentence form
- assist in finding synonym pivot terms — e.g. imatinib is the pivot term for the synonym cluster containing gleevec, sti571, db00619 etc.
- parenthetical neighbors may contain synonym term pairs that do not have explicit sentence evidence. Harvesting them may be hard given the number of parenthetical neighbors for a particular term. However, by identifying the entity type of each term in a parenthetical neighbor pair (using unsupervised NER for instance), one could create a noisy set of related candidates that includes those synonym terms. Conversely, a harvested synonym pair from sentences should, particularly for popular synonym pairs have corresponding parenthetical neighbor occurrences. Absence of that could be used to reduce the confidence of a synonym pair harvested from sentences — this is useful for the synonym pairs harvested from partial sentences, as mentioned earlier.
There has been recent work of unsupervised representation learning for relation extraction but it is too broad to apply for synonym harvesting where the required precision for relation extraction is high — it is just not enough to deduce there is a relation between the two terms just because they happen to be the same entity type — they need to be synonyms of each other. However, the idea of learning distributed representations of just relations is a powerful idea, particularly when fine tuned on a downstream supervised task.
Synonym harvesting is one of those rare problems whose feature complexity makes it possible even for traditional symbolic rules-base or template driven approaches to yield reasonable results regardless of their deficiencies. In particular such traditional approaches seem attractive at first since they avoid the need for labeled data — a requirement for supervised models. The approach described here leverages the power of distributed representations learnt by an unsupervised model to assist in a solution that is feature engineered in the symbolic space, even if only minimally. The approach, even if unsupervised, leverages off supervised models for constituency/ dependency parsing, POS tagging etc. These serve as critical tools in a practitioner’s toolbox and come in handy for a variety of tasks that are typically supervised like named entity recognition, synonym harvesting or relation extraction in general,.