Weather forecasting is the application of science and technology to predict the conditions of the atmosphere for a given location and time. Weather forecasts are made by collecting quantitative data about the current state of the atmosphere at a given place and using meteorology to project how the weather conditions will be. Once calculated by hand based mainly upon changes in barometric pressure, current weather conditions, and sky condition or cloud cover, weather forecasting now relies on computer-based models that take many atmospheric factors into account. Human input is still required to pick the best possible forecast model (machine learning model ) to base the forecast upon, which involves pattern recognition using the model, knowledge of model performance, and knowledge of model biases. This is the main aim of our project ; to compare various machine learning models and try to find which model gives the best performance for weather forecasting.
We have taken our dataset from Kaggle. The data contains hourly weather data of Delhi. It has actually been collected by using the API of the website “Weather Underground”.
DATA ANALYSIS
- In the data, there are 100990 instances and 20 features.
- The dates range from 01–11–1996 to 24–04–2017 and weather is recorded at regular intervals. Hence this dataset can be used as time series data as well as a normal classification problem.
- The column “_conds” has categorical values and represents the weather conditions of Delhi so we will take the dependent variable/ target variable as “_conds” that has been renamed as Conditions”. Rest all the features are independent variables and will be used to predict the weather condition.
- When we found the percentage of null values. Features with percentage >60% are as follows:
HeatIndex 71.13%
precipitationType 100.00%
Wgustm 98.93%
WindChillm 99.42%
From this we conclude:-
- We will drop columns with a high percentage of null values.
- We will have to handle the null values.
- The different types of values in the column and their respective counts are:
Examples:-
Name: Fog, dtype: int64
0 80791
1 5382
Name: WindDirection, dtype: int64
North 19034
West 11888
WNW 7464
East 7233
NW 7117
- There are two features- “Conditions” and “WindDirection” that have categorical values like smoke, Haze etc and North, south etc respectively. We will have to replace them with unique numerical values.
- We get the description of the data:-In “temperature” mean value is 25.451 and max value is 90, in humidity mean value is 57.9 and max value is 243. Here we see that the max value of temperature and humidity is unrealistic and hence some outliers are detected.
DATA PREPROCESSING
i) Importing Libraries and loading the data
- The libraries imported are pandas, numpy, matplotlib.pyplot, seaborn.
- The raw data is loaded into pandas dataframe.
ii) Time Series
- Weather data is from 01–11–1996 to 24–04–2017 and also for each day, it has hourly data, So it is basically data of a specified period of time with data points recorded at regular intervals and can be considered as time-series data.Format of ‘datetime_utc’ is changed to strftime(‘%Y-%m-%d %H’)and the index of the data frame is set to ‘datetime_utc’.
- It shows ‘index’ as an “object” type which needs to be converted to datetime otherwise we won’t be able to work during time series analysis.
ii) Data Cleaning
- Removing Outliers: In the data description, we discovered that the Maximum Value of Temperature is 90 and Humidity is 243, which is unrealistic (we can see that using the basic domain knowledge), so we need to remove the outliers. The data points with Temperature value <50 and Humidity value<=100 are only kept, and the unrealistic outliers are dropped.
- Treating Null values: The data has null values as we found during analysis so we will replace them with the mean of the corresponding columns.
- We again found that some features had null values:
Condition 72
WindDirection 14755
These two features have categorical values so drop the rows with null values.
iii) Feature Engineering
- Renaming the features to meaningful names like:-’ _conds’ to ‘’Condition’ and ‘ _tempm’ to ‘Temperature’.
- We will drop the features that have null percentage > 60% .Four features namely, “HeatIndex”, “precipitationType”, “Wgustm” and “WindChill” are dropped.
- The features “Condition” and “WindDirection” have categorical values So we replace them by unique numerical values .For example Smoke is replaced with 0, Haze is replaced with 1 and so on
Data Visualization and effect of preprocessing
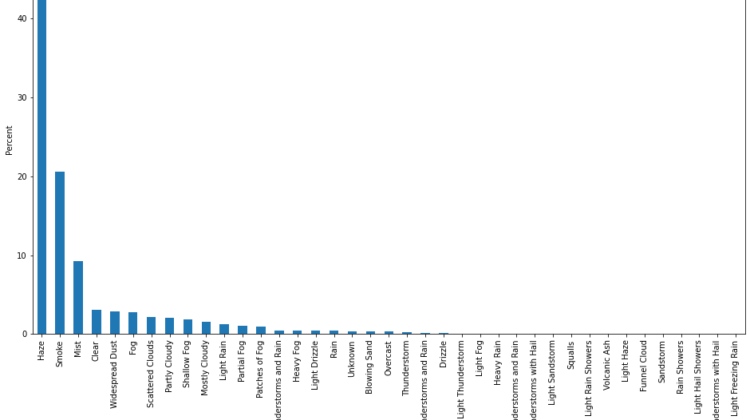
- Having a look on the weather conditions of Delhi from the original data itself:-
We can clearly see that Most of the time Delhi is either hazy or filled with smoke
- Let us consider a single attribute say “Temperature” and see the effect of preprocessing on it:
Raw Data:-
We can see a seasonal pattern in the timeseries. It is not continuous as it is having some missing data (ex: between 2000 and 2001).The long shoots that we can see in the graph are the outliers. After preprocessing:-
We can see that the outliers(long shoots) are removed. The missing data is filled in such a way that the seasonal pattern is maintained and data is useful and continuous
We can also see same for Humidity feature:
Before preprocessing:-
After preprocessing:-
Data Analysis after preprocessing:-
Shape of the data: 86177 rows and 15 features with no null values in any feature.
Goal: Classification based on weather conditions using different classification model.
Preprocessing: We have visualized the data using TSNE of 2 dimension, the data is not linearly separable. In the plot we can visualize the ’Condition’ column has 39 different classes.
We have chosen different target values like ’Temperature’ and ’Condition’ on which we have applied different models. We have chosen different columns as target variable because some columns are correlated with other columns. We have splitted the data into 70:30 ratio where 70 is for train set and 30 is for test set. We have used train test split from Sklearn to split the dataset.
Models and their Implementations:
(1.) Logistic Regression:
Model: Logistic Regression is one of the classification model to predict the probability of a target class. Logistic regression is used for binary classification. But If the data is Multiclass we will use the same idea of binary classification for the Multiclass Classification. This model will predict the class of dependent variable based on independent variable.
Implementation: We have used sklearn library for applying LogisticRegression model on our dataset. In our Model, The target columns we have chosen has multiple classes. So we have to apply ’ovr’ or ’multinomial’ as multi_class parameter in logistic regression model. We have set max iter=10000 so that solver may converge easily. This model is not very good for classification as we observed that the data is not separable using these features.
(2.) Support Vector Machine:
Model: Support Vector Machine can be used in classification. SVM is a supervised learning algorithm. The basic idea of using the SVM on our dataset is to create a decision boundary in n dimensional space of classes. The best decision boundary will be called as hyperplane. As we have visualized the data using TSNE, the data is not linearly separable so we will use Kernel Tricks for the classification. SVM will map our datapoints into the space and increase the distance between features present in the dataset.
Implementation: We have used sklearn library for applying SVC model on our dataset. In our Model, We have applied Grid search CV on the dataset and got the best parameters. We have got kernel as ’rbf’, C=1 and gamma=0.1. Then we have applied best parameter obtained from the GridSearchCV to our Model
(3.) K Nearest Neighbour:
Model: K- Nearest Neighbor can be used for Classification. An object will be classified using the majority voting of it’s k nearest neighbor. Here K is hyperparameter. This is a non parametric method. It is also an instance based learning algorithm. Here we have not use any underlying function while training. After visualizing data using TSNE we can visualize that there is some region where datapoints of a particular class are present. So we will be using the K nearest Neighbor on our Dataset.
Implementation: We have used sklearn library for applying KNeighborsClassifier on our dataset. We applied GridSearchCV for obtaining best hyperparameter. GridSearchCv returned n_neighbors=9 for the dataset. Then we have applied the best parameters on the KNN model using our dataset.
(4.) Decision Tree:
Model: Decision Tree is one of the classification algorithm used to predict the class of unknown datapoint by sorting them down into a Tree based structure from root to leaf. Leaf Node will decide the value of the class for the prediction. As there are 14 features remained after applying preprocessing on the dataset. So the decision tree will be a good option. We can predict the class of a unknown datapoint on the basis of traversal in a tree like structure. The tree is created using the most important features in the dataset. Decision making will be done on the basis of the leaf of the tree.
Implementation: We have used sklearn library for applying on our dataset. We have set the parameters in the classifier as Criterion =’entropy’. We obtained the Decision Tree using sklearn library.
(5.) Random Forest:
Model: The Random forest is also one the classification algorithm. This will be constructed using different structures of randomly selected Decision Tree, The ensemble method is applied on these trees. All the tree present in the Random Forest will predict the class for an instance individual tree. The class which will have highest number of votes will be known as the class of the instance. As there are 14 features remained after applying preprocessing on the dataset. So the random forest will be a good option. It will predict the class for the instance on the basis of the majority voting. Our goal is to predict the most accurate class for the datapoint.
Implementation: We have used sklearn library for applying RandomForestClassifier on our dataset. We have set the parameters in the classifier as n estimators=250, max depth=30 and Criterion as ’entropy’. We obtain the Random Forest Tree using sklearn library.
Results: