A visual walkthrough of the ensemble methods in machine learning with a cheatsheet
Let’s say you moved to a new place and want to dine out. How do you find a good place?
Solution 1: Find a food critic who is really good at his/her work and see if he/she has any recommendations for the restaurants in your area
Solution 2: Use Google and randomly look at one user’s review for a couple of restaurants.
Solution 3: Use Google and look at multiple users’ reviews for a couple of restaurants and average their ratings.
Let us analyze each of the above-mentioned solutions.
Solution 1:
- Food critics are in general much accurate.
- It is difficult to find a food critic
- Maybe the food critic you found was a strict vegetarian, and you are not. In that case, the recommendations from the food critic will be biased.
Solution 2:
On the other hand, picking up a random person’s star rating for a restaurant on the internet is
- Much less accurate
- Easier to find
Solution 3:
- Collectively it can be just the right amount of accuracy you need
- Easier to find over the internet
- Much less biased, since the users who have rated the restaurants come from various backgrounds.
Hence without the need to ask from a food critic, you can get a reasonably good recommendation on restaurants just by looking at a collective opinion of a group of random (but large) people. This is known as the wisdom of the crowd and is the backbone to various informative websites like Quora, Stack-exchange, and Wikipedia, etc.
Ensemble methods in Machine Learning use more than one weak learners collectively to predict the output. Instead of training one large/complex model for your dataset, you train multiple small/simpler models (weak-learners) and aggregate their output (in various ways) to form your prediction as shown in the figure below
Generally speaking, there are three different types of Ensemble Methods commonly used in ML these days
- Bagging
- Boosting
- Stacking
These methods have the same wisdom-of-the-crowd concept but differ in the details of what it focuses on, the type of weak learners used, and the type of aggregation used to form the final output.
1. Bagging
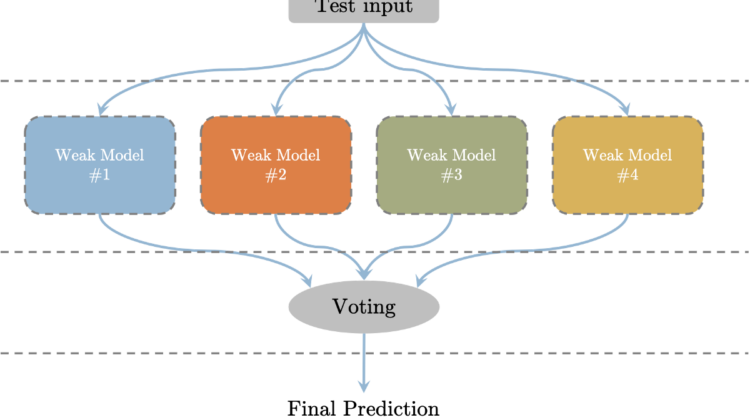
In Bagging (Bootstrap Aggerating), multiple weak-learners are trained in parallel. For each weak-learner, the input data is randomly sampled from the original dataset with replacement and is trained. A random sampling of the subset with replacement creates nearly iid samples. During inference, the test input is fed to all the weak-learners and the output is collected. The final prediction is carried out by voting on the outputs of each weak-learner.
The complete steps are shown in the block diagram below.
In bagging methods, the weak-learners, usually are of the same type. Since the random sampling with replacement creates iid samples, and aggregating iid variables doesn’t change the bias but reduces variance, the bagging method doesn’t change the bias in the prediction but reduces its variance.
2. Boosting
In boosting, multiple weak-learners are learned sequentially. Each subsequent model is trained by giving more importance to the data points that were misclassified by the previous weak-learner. In this way, the weak-learners can focus on specific data points and can collectively reduce the bias of the prediction. The complete steps are shown in the block diagram below.
The first weak-learner is trained by giving equal weights to all the data points in the dataset. Once the first weak-learner is trained, the prediction error for each point is evaluated. Based on the error for each data point, the corresponding weight of the data point for the next learner is updated. If the data point was correctly classified by the trained weak-learner, its weight is reduced, otherwise, its weight is increased. Apart from updating the weights, each weak-learner also maintains a scalar alpha that quantifies how good was the weak-learner in classifying the entire training dataset.
The subsequent models are trained on these weighted sets of points. One way of carrying out training on a weighted set of points is to represent the weight term in the error. Instead of using mean-squared error, a weighted mean-squared error is used ensuring that data points with higher assigned weight, are given more importance in being correctly classified. The other way could be weighted sampling i.e. sample points based on their weights when training.
In the inference phase, the test input is fed to all the weak-learners and their output is recorded. The final prediction is achieved by scaling each weak-learner’s output with the corresponding weak-learner’s weight alpha before using them for voting as shown in the diagram above.
3. Stacking
In stacking, multiple weak-learners are trained in parallel, which is similar to what happens in bagging. But unlike bagging, stacking does not carry out simple voting to aggregate the output of each weak-learner to calculate the final prediction. Rather, another meta-learner is trained on the outputs of weak-learners to learn a mapping from the weak-learners output to the final prediction. The complete block diagram can be seen below.
Stacking usually has weak-learners of different types. Hence a simple voting method that gives equal weights to all the weak-learners prediction doesn’t seem like a good idea (it would have been if the weak-learners were identical in structure). That is where the meta-learner comes in. It tries to learn which weak-learner is more important.
The weak-learners are trained in parallel, but the meta learner is trained sequentially. Once the weak-learners are trained, their weights are kept static to train the meta-learner. Usually, the meta-learner is trained on a different subset than what was used to train the weak-learners.
The following cheat sheet covers the topic of Ensemble methods that might come in handy.
Instead of training one network, Ensemble methods use multiple weak-learners and aggregate their individual output to create final predictions. A comparison of different Ensemble methods can be seen in the table below.