A good machine learning (ML) product team is made up of multiple specialties; from research, engineering and dev, to design, strategy, product management and more. These specialities can help identify each others’ blind spots (re building products that are simultaneously desirable, feasible and viable), define a roadmap for successful innovation, and collaborate towards its execution. On the other hand, the relative newness of ML products — particularly in certain domains, industries, and companies — means that such teams do not have access to rich knowledge bases (e.g., of know how, case studies, individual experience, and best practices) that more traditional apps and products (e.g., in consumer internet) do have access to and can learn from. While time will enrich the community’s shared knowledge base (e.g., by offering more case studies, anecdotes, …), taking inspirations from other domains can be a solution to this problem in the short (to medium) term; domains that take novel scientific concepts with uncertainties (and potential transformative effects) to the market.
In ML products, models are amongst the key features without which the product might not be successful. In AI-first products, this will go even further: There will be no product without some effective ML models. Therefore, it is quite common for the product teams to aspire to push the model accuracy (e.g., through model search, more data, and incorporation of more prior knowledge) above a certain threshold (e.g., 90% areas under the ROC curve for a classifier). While one can expect a more accurate model to be more useful than a less accurate one, the reality, however, can challenge this view of simple one-dimensional accuracy-based model selection. For instance, such accuracy metrics are not usually homogeneously distributed across various subgroups in the sample/population; practical considerations (e.g., speed and cost of preparing the model inputs) can make the mapping between such ML metrics and downstream product/business metrics less linear (and even less monotonic) and dependant on a range of other factors (usually less scientific, and more driven by UX and commercial realities). This leads to to questions around best practices: How should one determine a good/useful/effective/accurate model for ML/AI products?
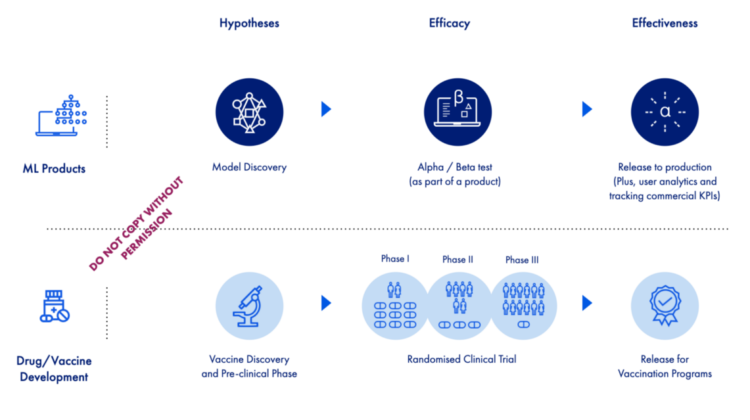
The good news is that such problems are not unique to modern ML products; domains such as medicine have faced them in different forms, and hence might be able to help provide answers/inspirations. For instance, let’s consider the evaluation of interventions such as a vaccines, which has become a mainstream conversation these days. The process is likely to go through multiple stages: Starting with a pre-clinical phase to generate and assess some hypotheses (which can result in many candidates that are likely to work) ; going to phases of randomised clinical trials (or RCTs, for the assessment of safety and efficacy); and ending with mass distribution (which will only happen to a very small percentage of the pre-clinical and trialed candidates). During the mass roll out, such a vaccine will be assessed for its effectiveness (i.e., phase IV clinical trial); unlike efficacy, which aims to estimate the vaccine’s risk reduction in a well-controlled/-monitored setting (i.e., where people are likely to do what they are asked to), effectiveness does this assessment in a real-world setting (where people might not adhere with the guideline, and there is minimal control and monitoring in place, and so on). Of course, this story and approach is not unique to vaccines and is how trust is built and reevaluated for medical interventions in general.
Remember the famous “everything is a remix”? Well, I think what ML products experience these days — from training a model on observational offline data (e.g., in Jupyter notebooks), all the way to its final production/release, and the assessment of its effectiveness — has many similarities to what many medical tests/products/procedures/interventions go through before their approval. Therefore, below are 10 points that I think can help ML products draw parallels between these two worlds.
- Almost all software products have unknowns — prior to their production / going live — with regards to their effectiveness in improving some metrics (e.g., commercial or operational KPIs). I think that ML products have additional sources of unknown that goes beyond non-ML products (given the degrees of uncertainties in, and the accuracy of their predictions, plus the nature of their relationship with users’ decision making).
- We can consider three modes of ML products: (A) Inform mode (i.e., helping users do better, through giving them the right information at the right time); (B) assist mode (i.e., doing things on behalf of their users; as in partial or full automation); and © reimagination mode (redesigning and reimagining the way a business / an operation happens, given what ML can do in that context). All three of these scenarios can be subject to thorough evaluation (i.e., similar to what they do in medicine for estimating efficacy and effectiveness), when it comes to some ML models’ effect in driving commercial success.
- Today, inform mode is probably one of the most common (and desired) modes in high-stake decision making (e.g., health and finance) and enterprise software. This is the scenario that I think is most similar to interventions in medicine, when it comes to evaluating how much of the results can be attributed to AI and how much of it is due to other factors.
- Why does the estimation of efficacy and effectiveness matter? Building ML models and maintaining them in production is considered a significant investment by many firms (from time, data, talent, and research to change management and transition/transformation that follows); being able to calculate such investments’ ROI (and their viability over time) plays a key role in justifying such investments. Furthermore, the users’ ability to let ML influence their decisions will depend on their understanding of such models’ strengths and weaknesses; such calculations can help build and strengthen the trust between the users and ML.
- Of course, I don’t think that every ML feature in a product should go through the assessments that clinical interventions go through. Imagine an isolated task that ML does with near-perfect accuracy in offline data; assuming that users’ interaction with the product will not influence neither model’s performance nor users’ decision making, and the real-world data are very similar to the one the model is trained and evaluated on (e.g., no drift); such features can be simply rolled out based on research evidence.
- Another category where the need for such thorough investigations will be less is when the cost of type I and type II errors are very low (e.g., many-user, high-volume, low-stake and inconsequential predictions, such as many examples in consumer internet, for instance); here, for instance, one can directly optimise on commercial metrics (a la A/B testing), as opposed to RCT-like processes.
- As mentioned earlier, when the stakes are high and users and models are so intertwined in driving the end result, an approach to quantify the impact of the model will be critical. As a first step in this direction, ML products need to define the commercial “end point(s)” they plan to optimise for; efficacy and effectiveness are defined based such end points.
- Given the end points and an ML model, product teams can benefit from a set of hypotheses re how to go from predictions to commercial end points; this will help them identify the most promising models to be taken to the expensive RCT-like evaluation process. Of course, as part of a UX research and as a temporary process, one can have the users interact with models, in order to identify such end-point hypotheses (and quickly test some, a la lean methodology).
- Given a set of promising models (and their associated UX hypotheses), products can learn from experiment design approaches that medical researchers have perfected over the past decades to assess efficacy; this article reviews a long list of such techniques for both observational and interventional study designs. Note that, there are already papers on and research towards more thorough scientific rigour for A/B tests in complex circumstances (see this paper, for instance).
- Of course, this does not guarantee there to be a solution for all such problems. For instance, some end points need a long wait time (for instance, when ML predicts a company’s risk of default in finance, or the risk of dementia in medicine), which takes them beyond the scope of such RCT-like evaluations. In such circumstances, focus on shorter-term end points (e.g., improvements to some operational KPIs) or alternative ones (e.g., credit events instead of default in finance, or size of hippocampus instead of clinical diagnosis of dementia) might help. Furthermore, there are products that deal with a small number of users and a low volume of decisions, which will make the collection of required samples to estimate efficacy and effectiveness a challenge.
This is the fifth article in a series of posts that I wrote about the development of AI-first products (and AI-first digital transformation) — challenges, opportunities, and more. I would love to hear your thoughts, and any learning and experiences you and your company might have in this space. Get in touch! Of course, this is a personal opinion and does not necessarily reflect the viewpoints of AIG (or the University of Oxford).