Decision Tree is one of the most popular and powerful classification algorithms that we use in machine learning. As the name itself signifies, decision trees are used for making decisions from a given dataset. The concept behind the decision tree is that it helps to select appropriate features for splitting the tree into subparts similar to how a human mind thinks.
To build the decision tree in an efficient way we use the concept of Entropy/Information Gain and Gini Impurity. To know more about Entropy/Information Gain, you may want to read my Entropy blog.
In this blog, let’s see what is Gini Impurity and how it is used to construct decision trees.
What is Gini Impurity?
The Gini impurity measure is one of the methods used in decision tree algorithms to decide the optimal split from a root node, and subsequent splits. It is the most popular and the easiest way to split a decision tree and it works only with categorical targets as it only does binary splits.
Gini Impurity is calculated using the formula,
Lower the Gini Impurity, higher is the homogeneity of the node. The Gini Impurity of a pure node(same class) is zero.
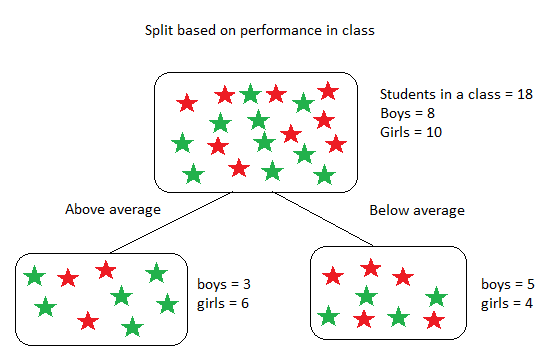
To calculate Gini impurity, let’s take an example of a dataset that contains 18 students with 8 boys and 10 girls and split them based on performance as shown below.
The calculation of Gini Impurity of the above would be as follows:
In the above calculation, to find the Weighted Gini Impurity of the split (root node), we have used the probability of students in the sub nodes, which is nothing but 9/18 for both “Above average” and “Below average” nodes as both the sub nodes have equal no of students even though the count of boys and girls in each node varies depending on their performance in class.
Following are the steps to split a decision tree using Gini Impurity:
- Similar to what we did in entropy/Information gain. For each split, individually calculate the Gini Impurity of each child node
- Calculate the Gini Impurity of each split as the weighted average Gini Impurity of child nodes
- Select the split with the lowest value of Gini Impurity
- Until you achieve homogeneous nodes, repeat steps 1–3
To summarize on Gini Impurity :
- It helps to find out the root node, intermediate nodes and leaf node to develop the decision tree
- It is used by the CART (classification and regression tree) algorithm for classification trees.
- It reaches its minimum (zero) when all cases in the node fall into a single target.
To conclude, Gini Impurity is preferred over Entropy/Information gain because of its simple formula that does not use logarithms which are computationally intensive and difficult.
Happy Decision Making!