Regularization helps to overcoming a problem of overfitting a model.Overfitting is the concept of balancing of bias and variance. If it is overfitting , model will have less accuracy.When our model tries to learn more property from data, then noise from the training data is added.Here noise means the data point that don’t really present the true property of your data.
Different Regularization Technique:
- L1 and L2 Regularization
- Dropout
- Data Augmentation
- Early stopping
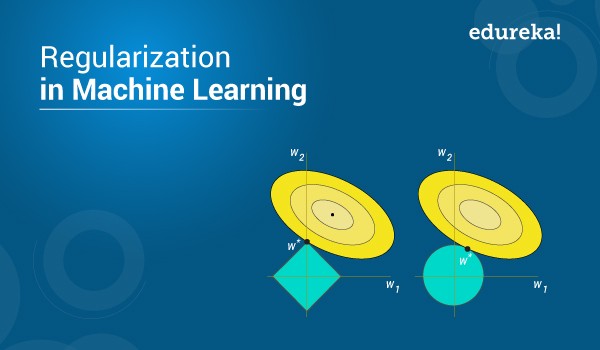
It is the most common type of regularization.In regression model , L1 regularization is called Lasso Regression and L2 is called Ridge Regression.
These update the general cost function with another term as regularization.
Cost function = Loss ( cross entropy) + regularization
Here, lambda is the regularization parameter. It is the hyper-parameter whose value is optimized for better results. L2 regularization is also known as weight decay as it forces the weights to decay towards zero (but not exactly zero).
It is most frequently used regularization technique in the field of deep learning.At every iteration, dropout select some node and drop that along with all incoming and outgoing connections.So each iteration have different set of node with output.In machine learning this is called ensemble that have better performance as they capture more randomness.
Early stopping is a kind of cross-validation strategy where we keep one part of the training set as the validation set. When we see that the performance on the validation set is getting worse, we immediately stop the training on the model. This is known as early stopping.
The main advantage of using regularization is that it often results in a more accurate model. The major drawback is that it introduces an additional parameter value which must be determined, the weight of the regularization.