Data scientists spend a significant amount of time creating training datasets and data pipelines related to ML model features.
Let me start off by sharing three experiences from the real-world:
Training Set Generation: During model training, datasets consisting of one or more features are required to train the model. The training set, which contains the historic values of these features, is generated along with a prediction label. The training set is prepared by writing queries that extract the data from the dataset sources and transform, cleanse, and generate historic data values of the features. A significant amount of time is spent on developing the training set. Also, the feature set needs to be updated continuously with new values (a process referred to as backfilling).
Managing a pipeline jungle related to ML features: As a part of the exploration phase, data scientists search for available features that can be leveraged to build the ML model. The goal of this phase is to reuse features and reduce the cost to build the model. The process involves analyzing whether the available features are of good quality and how they are being used currently. Due to a lack of a centralized feature repository, data scientists often skip the search phase and develop ad hoc training pipelines that have a tendency to become complex over time. As the number of models increases, it quickly becomes a pipeline jungle that is hard to manage.
Feature Pipeline for Online Inference: For model inference, the feature values are provided as input to the model, which then generates the predicted output. The pipeline logic for generating features during inference should match the logic used during training, otherwise, the model predictions will be incorrect. Besides the pipeline logic, an additional requirement is having a low latency to generate the feature for inferencing in online models. Today, the feature pipelines embedded within the ML pipeline are not easily reusable. Further, changes in training pipeline logic may not be coordinated correctly with correspond‐ ing model inference pipelines.
Building data pipelines to generate the features for training, as well as for inference, is a significant pain point. First, data scientists have to write low-level code for accessing datastores, which requires data engineering skills. Second, the pipelines for generating these features have multiple implementations that are not always consistent — i.e., there are separate pipelines for training and inference. Third, the pipeline code is duplicated across ML projects and not reusable since it is embedded as part of the model implementation. Finally, there is no change management or governance of features. These aspects slow down ML projects — data users (scientists, analysts) typically lack the engineering skills to develop robust pipelines and monitor them in production. Also, feature pipelines are repeatedly built from scratch instead of being shared across ML projects. The process of building ML models is iterative and requires exploration with different feature combinations.
The time spent by the data team is broadly divided into two categories: feature computation and feature serving. Feature computation involves data pipelines for generating features both for training as well as inference. Feature serving focuses on serving bulk datasets during feature training and making it easy for data users to search and collaborate across features.
Feature computation is the process of converting raw data into features. This involves building data pipelines for generating historic training values of the feature as well as current feature values used for model inference. Training datasets need to be continuously backfilled with newer samples. There are two key challenges to feature computation.
First, there is the complexity of managing pipeline jungles. Pipelines extract the data from the source datastores and transform them into features. These pipelines have multiple transformations and need to handle corner cases that arise in production. Managing these at scale in production is a nightmare. Also, the number of feature data samples continues to grow, especially for deep learning models. Managing large datasets at scale requires distributed programming optimizations for scaling and performance. Overall, building and managing data pipelines is typically one of the most time-consuming tasks in model creation.
Second, separate pipelines are written for training and inference for a given feature. This is because there are different freshness requirements, as model training is typically batch-oriented, while model inference is streaming with near real-time latency. Discrepancies in training and inference pipeline computation is a key reason for model correctness issues and a nightmare to debug at the production scale.
In a typical large-scale deployment, feature serving supports thousands of model inferences. Scaling performance is one of the key challenges, as is avoiding duplicate features given the fast-paced exploration of data users across hundreds of model permutations during prototyping.
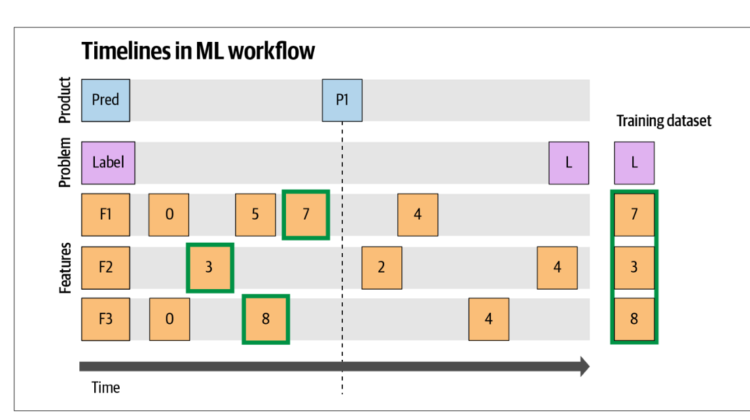
Today, one of the common issues is that the model performs well on the training dataset but not in production. While there can be multiple reasons for this, the key problem is referred to as label leakage. This arises as a result of incorrect point-in- time values being served for the model features. Finding the right feature values is tricky. To illustrate, Zanoyan et al. cover an example illustrated in Figure. It shows the feature values selected in training for prediction at Time T1. There are three features shown: F1, F2, F3. For prediction P1, feature values 7, 3, 8 need to be selected for training features F1, F2, F3, respectively. Instead, if the feature values post- prediction are used (such as value 4 for F1), there will be feature leakage since the value represents the potential outcome of the prediction, and incorrectly represents a high correlation during training.
Ideally, a feature store service should provide well-documented, governed, versioned, and curated features for training and inference of ML models. Data users should be able to search and use features to build models with minimal data engineering. The feature pipeline implementations for training as well as inference are consistent. In addition, features are cached and reused across ML projects, reducing training time and infrastructure costs. As the feature store service is built up with more features, it provides economies of scale by making it easier and faster to build new models.
Feature store services are becoming increasingly popular: Uber’s Michelangelo, Airbnb’s Zipline, Gojek’s Feast, Comcast’s Applied AI, Logical Clock’s Hopsworks, Net‐ flix’s Fact Store, and Pinterest’s Galaxy are some of the popular open-source examples of a feature store service. A good list of emerging feature stores is available at featurestore.org.
Building a Feature Store and making it self-service to data users involves implementing two patterns defined as Maslow’s hierarchy (as shown in the figure below):
- Hybrid feature computation pattern: Defines the pattern to combine batch and stream processing for computing features.
- Feature registry pattern: Defines the pattern to serve the features for training and inference.
For details of these patterns and experiences in making it self-service, refer to my O’Reilly book: The Self-Service Data Roadmap.