Researchers in multiple communities (machine learning, formal methods, programming languages, security, software engineering) have embraced research on model robustness, typically cast as safety or security verification. They make continuous and impressive progress toward better, more scalable, or more accurate techniques to assess robustness and prove theorems, but the many papers I have read in the field essentially never talk about how this would be used to actually make a system safer. I argue that this is an example of the streetlight effect: We focus research on robustness verification, because it has well-defined measures to evaluate papers,whereas actual safety and security questions are much harder and require to consider the entire system, not just properties of the model. When thinking of testing, safety and security of production machine learning systems, we need to step beyond narrow measures of robustness.
We have probably all seen examples of how easily machine learning models can be fooled into making wrong predictions by adding slight noise to the input that may be imperceptible to humans, such as this panda recognized (with high confidence) as a gibbon when some minor noise that’s pretty much invisible to humans is added:
In a nutshell, the problem occurs, because we learn and use models without understanding how they work internally and whether they actually learn concepts that would mirror human cognition. The models tend to work on average (as our accuracy measures indicate during model evaluation), but we often really do not know why and how — and maybe we don’t care as long as they mostly work. However, since we don’t know and cannot specify how these models work, we can always find examples of wrong predictions, where the model simply does not produce the expected result. Worse, with suitable search, it is often possible to find small variations of a specific input that change the model’s prediction. This is known as adversarial examples, and there is a huge amount of research on how to find them, with and without access to the model’s internals.
While the panda-gibbon example might look fun, it is easy to reframe adversarial examples as safety and security problems. For examples, researchers have shown that small stickers taped to a stop sign can fool a vision system to recognize the sign as a “Speed Limit 45” sign, implying that this might lead to wrong and dangerous actions taken by an autonomous car:
Beyond intentional attacks by manipulating inputs, also natural changes to inputs may lead to wrong predictions with safety consequences. The most common examples are self-driving cars driving in foggy weather conditions or with a slightly titled or smeared camera, all resulting in small modifications of the input. For example, researchers have shown how simple transformations of the image (mirroring possible real-world problems) can lead to wrong predictions of the car’s steering angle:
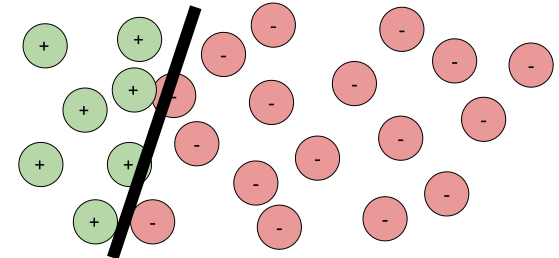
In this context, robustness is the idea that a model’s prediction is stable to small variations in the input, hopefully because it’s prediction is based on reliable abstractions of the real task that mirror how a human would perform the task. That is, small invisible noise should not flip the prediction from panda to gibbon, small additions to the image should not prevent the model from recognizing a stop sign, and weather conditions or slightly titling the camera should not affect the steering angle of a self-driving car.
Side note: I like Goodfellow et al.’s visual explanation of adversarial examples as a mismatch between the actual decision boundary (ground truth/specification) and the model’s learned decision boundary. Unfortunately, we use machine learning exactly because we don’t have a clear specification and don’t know the actual decision boundary (see my discussion of specifications in Machine Learning is Requirements Engineering). Hence the explanation is a nice conceptual view, but not very helpful in a practical setting, where we care about whether a prediction is correct. Robustness relates only to the question whether we are near the model’s decision boundary, without knowing anything about the actual decision boundary.
Robustness is an appealing property to study, because it is easy to define well as an invariant over the relation of two inputs (technically a metamorphic relation) without having to rely on specifications and ground truth of what the actual correct prediction is.
All local robustness properties more or less follow this form: Given an input x and a model f of interest, we want the model’s prediction to stay the same for all inputs x’ in the neighborhood of x, where the neighborhood is defined by some distance function δ and some maximum distance Δ:
∀ x’. δ(x, x’)≤Δ ⇒ f(x)=f(x’)
The way the distance is defined may differ a lot based on the problem. Typical examples allow for low amounts of noise to all input features (e.g., all pixels), arbitrary changes to few input features (e.g., change any three pixels), or more complicated transformations (e.g., tilting the picture or adding “fog”). Whatever the possible transformations or corresponding distance functions and maximum distance, we always reason about some neighborhood around the original input.
Note that this definition does not require any information about what the correct prediction for f(x) or f(x’) is, we simply reason about the fact that the prediction shall stay consistent (whether correct or not) within a neighborhood.
Robustness is either established as a binary property, i.e., an input for a model is verified as robust or not (usually conservative overapproximations, but also probabilistic judgments with a confidence level have been proposed), or as some form of relative measure, e.g., the distance to the nearest adversarial example or the percentage of robust inputs in the neighborhood.
Researchers now developed many different search and verification strategies to evaluate this robustness property for deep neural networks. This can be done by searching for adversarial examples within the neighborhood, by simply sampling and testing a large number of data points in the neighborhood, or by different forms of formal verification that formally prove that no point in the neighborhood can change the prediction result.
Notice that robustness research focuses essentially exclusively on deep neural networks, because this is where it is hard to scale proof techniques. In contrast, I’m not aware of robustness papers on decision tress or linear models and it seems that robustness evaluations would be fairly straightforward to implement and fairly scalable for many such models — I suspect that’s why I haven’t seen such papers.
In addition to local robustness, some researchers have also discussed a global robustness property of a model, typically some form of average robustness for all possible inputs. For example, one could measure for what percent of inputs robustness can be verified or what the average distance is from each input to the nearest adversarial example.
Side note: As studied by Borg et al.: Robustness is a term that practitioners use a lot, but usually just vaguely referring to correctness or trustworthiness of the model’s predictions, not the formal notion of robustness studied in the research literature and discussed here.
I have read dozens of papers analyzing robustness of machine-learned models and most of them motivate the analysis with safety and security concerns — yet none of those papers discussed or even evaluate how robustness would be really used in a practical setting.
First of all, robustness is difficult to interpret. The only model that is fully robust for all inputs is the trivial model that returns the same prediction for all outputs. For all other models, there is a decision boundary and some inputs will be close to the model’s decision boundary and hence not robust: some parts of the neighborhood of inputs near the decision boundary will be on each side of the decision boundary.
Use case 1: Evaluating robustness at inference time
The most plausible usage scenario seems to be to evaluate robustness at inference time, that is, check whether a given prediction made by a system during its operation is robust. For example, when labeling images, we could only label those images for which we have proof or confidence that the label is robust to minor perturbations (independent of the confidence score the model may already provide) and thus decide not abstain from labeling the panda in the image above. Similarly, we could identify that the stop sign is not robustly identified as a stop sign and thus not trust it as any sign for decisions made by the self-driving car.
This seems appealing and robustness can be a powerful tool, but to actually use it for safety and security of systems, engineers need to solve multiple additional problems:
- Costly analysis: State of the art robustness analysis for deep neural networks is very costly. Even though techniques get better, they currently scale only to small and mid-sized neural networks (handwritten digit recognition anyone?) and they typically take minutes to analyze robustness of a single input, due to the cost of the formal analysis, the SMT solving, or the huge number of samples needed. We can certainly hope for research progress to continue to reduce the cost, but it’s hard for me to imagine anybody to use robustness evaluations any time soon at inference time; not for high-volume systems like tagging photos at Facebook and certainly not for real-time applications as self-driving cars.
- Defining maximal distance: Defining a suitable distance function and threshold for the size and shape of the neighborhood is a nontrivial engineering problem. The larger the neighborhood, the more predictions will be classified as not robust. If the neighborhood is too small, attacks and accidental misclassifications are more likely to slip through. Also what perturbations are plausible to occur in practice due to accidents or attacks and how to define the right neighborhood? What are the worst cases we want to protect against? Identifying the right distance function and maximum distance threshold are nontrivial engineering challenges.
- Robust≠safe: If we analyze robustness at inference time and we have found a reasonable maximal distance, what do we do with model predictions that determined as being not robust? We could simply decide not to label the image, but we cannot just stop steering the self-driving car. Also, are we assuming that a prediction will be correct, just because it is robust? We clearly need to think about safety mechanisms beyond the model, still anticipating that the model may make wrong predictions or simply indicate more often that it is not sure.
Notice that the cost argument may not apply to simpler ML models such as decision trees, though I have not seen anybody discuss using robustness at inference time for those either. I would really be interested in seeing projects that try to design safe systems and discussions how they address these challenges.
Use case 2: Global model assessment
It is possible to evaluate the average robustness of a model for arbitrary inputs, measured as some global robustness property. We might consider this as an additional measure of model quality, in addition to prediction accuracy (ROC, recall/precision, lift, MAPE, whatever), where robustness and accuracy measure very different qualities. Note that the evaluation can be done entirely offline; cost may be high, but this strategy does not slow down model inference in production.
A model that is on average more robust may be preferable, because it may be assumed to learn more actual concepts, be restricted to fewer simpler decision boundaries, or may be affected less by noise or attacks.
Challenges now come from how to measure and meaningfully interpret global robustness. Do we really care about all inputs equally, or shall robustness focus on more common inputs? For example, many approaches have been used to generate synthetic “test” inputs that are not robust, but do we really care about random inputs that do not resemble any real-world inputs? Also similar to accuracy measures, what level of robustness is considered good? What neighborhood size should be used? How would we make tradeoffs between accuracy and robustness? Overall, global model robustness is easy to define as a metric, but it is unclear how to make use of that metric.
And finally, say we have established high average robustness, how does this help us make any safety or security claims? We hope that the model makes fewer mistakes or is harder to attack, but we do not know anything about a specific prediction at inference time. In a practical setting, an attacker may very well be able to find adversarial examples for many actual inputs.
Use case 3: Debugging the model
Instead of evaluating robustness globally (use case 2), we can evaluate robustness of a set of actual inputs. For example, we could evaluate the robustness of every single input in the validation data set (hopefully representative of actual inputs in production) or even in the training set. We could also analyze robustness of a sample of inputs received in the production system, say, random inputs or inputs flagged as problematic through the system’s telemetry (e.g., users reported predictions as incorrect).
Knowing whether certain predictions on sample inputs are robust may help us with debugging. We might identify areas of inputs for which many predictions are not robust — either because they are truly close to the real decision boundary or, more likely, because the model is simply not very good at understanding these inputs. We might identify dangerous conditions, such as the inability of our model to deal with fog — hopefully identified during testing not in production.
If we understand problems of the model, we may then try to improve the model. The most common strategy seems to be data augmentation, where inputs from the neighborhood of training inputs are added to the training data. Changes to the model architecture or feature engineering may also help to nudge the model to learn more relevant concepts. Many many papers explore different approaches here.
Overall, this seems a promising strategy to debug, harden, and generally improve models. A key challenge is the question of which inputs should be used for robustness analysis (leading to hard questions about curating a good test set) and, as above, how to define the maximum distance to consider. Also similar to use case 2, we won’t have any robustness guarantees about how the model behaves in production. None of this improves a system’s safety or security by itself.
Safety and security are system properties, not properties of software or machine-learned models. As safety research Nancy Leveson (MIT) puts (repeatedly) it in her ICSE’20 keynote talk:
“Software is not unsafe. It can contribute to a hazard, but it does not explode, catch on fire, involve toxic materials, etc. If it is not about hazards, it is not about safety. […] Software is not unsafe; the control signals it generates can be. […]
It is not possible to look at software alone and determine safety […] Virtually all software-related accidents have resulted from unsafe requirements, not software design/implementation errors.”
Safety is all about building safe systems, often from unreliable components, including software and hardware components. It is about making sure that the system overall is safe, even if a component fails (e.g., hardware failure, a model makes a wrong prediction) or unanticipated interactions arise among multiple components.
Given that we cannot specify the expected behavior of a machine-learned model and cannot verify it’s functional correctness, the safety question must concern how the system interacts with the environment based on outputs from machine-learned models that are often unreliable. We must think about safeguards outside the model, such as a thermal fuse or maximal toasting duration in a smart toaster that ensures that the toaster does not catch fire no matter what it’s internal model predicts as toasting times.
Engineering safe systems requires understanding requirements at the system level, analyzing the interactions between the world and the machine, as well as understanding the interactions of various (possibly unreliable) components. It is the context of how the model is used that determines whether the model is safe.
Model robustness does ensures neither safety nor security itself. Robustness ensures nothing about “correctness” of a model: robust predictions can still be wrong; a very robust model can be completely useless. Robustness may be a useful building block in a larger safety story (with all the open engineering challenges discussed above), since it changes assumptions we can make about an ML component when we consider interactions with other parts of the system and the environment. But only making a model robust does not make the system safe.
There is research work on building safe systems with machine-learned models, especially around avionics and self-driving cars—it’s all about requirements and system design and system-level testing, whereas assuring a formal robustness property usually does not seem to be much of a concerns there.
So back to the streetlight effect: Robustness of deep neural networks is a thankful research topic because it is well defined, challenging, with room for clearly measurable improvements over the state of the art. Many researchers have made incredible contributions. However, if we are really concerned about safety and security of production systems with machine-learning components, we should look beyond the simple and well-defined problems at the real and ugly engineering challenges of real-world systems.
Further readings:
- My prior posts on quality assurance of ML-enabled systems: Machine Learning is Requirements Engineering (on the notion of correctness and the role of specifications), A Software Testing View on Machine Learning Model Quality (on testing strategies beyond accuracy), The World and the Machine and Responsible Machine Learning (on system-level thinking and requirements engineering)
- Paper surveying safety engineering for ML systems in current automotive engineering: Borg, Markus, Cristofer Englund, Krzysztof Wnuk, Boris Duran, Christoffer Levandowski, Shenjian Gao, Yanwen Tan, Henrik Kaijser, Henrik Lönn, and Jonas Törnqvist. “Safely entering the deep: A review of verification and validation for machine learning and a challenge elicitation in the automotive industry.” Journal of Automotive Software Engineering. Volume 1, Issue 1, Pages 1–19. 2019
- Paper on safety engineering and architectural safety patterns for autonomous vehicles: Salay, Rick, and Krzysztof Czarnecki. “Using machine learning safely in automotive software: An assessment and adaption of software process requirements in ISO 26262.” arXiv preprint arXiv:1808.01614 (2018).
- Another paper discussing different safety strategies for autonomous vehicles: Mohseni, Sina, Mandar Pitale, Vasu Singh, and Zhangyang Wang. “Practical Solutions for Machine Learning Safety in Autonomous Vehicles.” SafeAI workshop at AAAI’20, (2020).
- Survey paper listing many recent robustness verification techniques (in Sec 4): Huang, Xiaowei, Daniel Kroening, Wenjie Ruan, James Sharp, Youcheng Sun, Emese Thamo, Min Wu, and Xinping Yi. “A survey of safety and trustworthiness of deep neural networks: Verification, testing, adversarial attack and defence, and interpretability.” Computer Science Review 37 (2020).
- Annotated bibliography on software engineering for AI-enabled systems including several papers on robustness, security, and safety