There are two main considerations when it comes to adopting TFX: value and cost. I want to demonstrate the value of TFX and how it helps with production-level experimentation, and adopting the best standards for model and data validation.
The cost for using TFX is all about locking up Machine Learning to Tensorflow stacks, such as model training and data transformation. Moving to Tensorflow from RAM-based Pandas, scikit-learn, and R-Studio may become a not-so-trivial endeavor, and seeing the potential value of TFX clearly is very important. So, here it is!
Two TFX examples:
1. With Kubeflow:
https://github.com/kubeflow/pipelines/tree/743746b96e6efc502c33e1e529f2fe89ce09481c/samples/core/parameterized_tfx_oss
2. Local mode (no Kubeflow installed): https://github.com/romankazinnik/romankazinnik_blog/tree/master/TFX_KFP
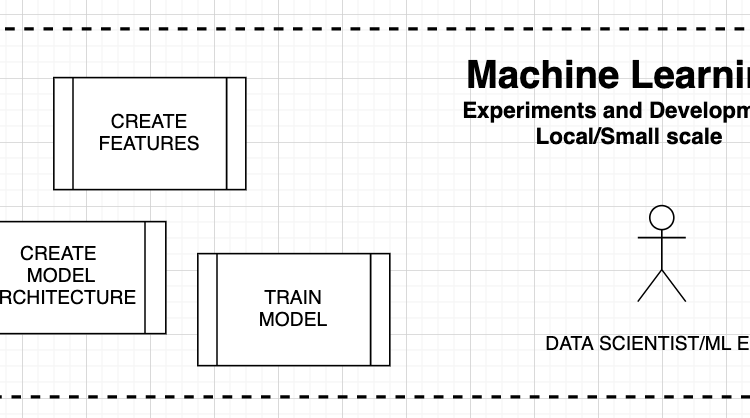
Data Science Experiments as opposed to Production Large-Scale Experiments, Train and Inferences
WORLD WITHOUT TFX — DATA SCIENTISTS AND ENGINEERS, MANY PER SINGLE PRODUCT
Data Scientists (DS):
- DS: run experiments locally to find high-accuracy features, models
- DS: find data transformations
- DS: work with Machine Learning frameworks such as supervised ML, unsupervised ML, active learning, reinforcement learning
- Engineers: often create custom production workflow to manage models and data in Live deployment
By adopting Tensorflow and TFX as the standard, Data Scientists create ML pieplines ready for Live deployment:
– DS Experiments: can be run locally and on cluster
– Model management: Train, Inferences is done by TFX
– Kubeflow: TFX can run with and without Kubeflow
– Cluster: integrated with TFX
– Value — minimize disconnect DS-Engineers and make irrelevant the eternal ML questions “BUT IT WORKS ON MY LAPTOP”